
Right around the release of GPT-5.5, Claude finally admitted it:
Yes, the model got “dumber,” and all usage quotas have been reset.
After over a month of denial, the intelligence drop bug finally came straight from Anthropique itself:
- Reasoning level quietly downgraded from “high” to “medium”
- A caching bug wiped thinking traces every turn
- A 25-word prompt limit crushed output quality
Stack those three bugs together, and Claude’s overall experience took a serious hit.
Good thing competitors applied pressure at just the right moment. Trying to “educate users” clearly wasn’t going to work.
Still, fixing bugs is always a good thing. It’s just… the timing is suspicious. GPT-5.5 drops, and suddenly Claude “admits defeat.”
Was 5.5 helping debug?
Dario… you didn’t intentionally make Claude worse just to set up a comeback moment when GPT-5.5 launched, did you?
Three confirmed bugs behind Claude’s performance drop
First, this isn’t the first time.
Back in August last year, Anthropic published a similar postmortem affecting Opus 4.0 and 4.1, also stating “we never intended to reduce model quality.”
This time, the new postmortem is titled “A postmortem of three recent issues.”
“Recent” is key — not just now, but over the past period.
The community had already noticed
Claude getting worse had been widely discussed for a while.
Over ten days ago, AMD AI senior director Stella Laurenzo published a deep audit on GitHub:
- 6,852 conversations
- 17,871 reasoning blocks
- 230,000+ tool calls
The findings: since February, reasoning depth dropped sharply.
More detailed observations:
- Claude started falling into reasoning loops
- It increasingly chose the simplest fix, not the correct one
Meanwhile, BridgeMind’s BridgeBench benchmark showed Opus 4.6 accuracy falling from 83.3% to 68.3%, ranking from #2 to #10.
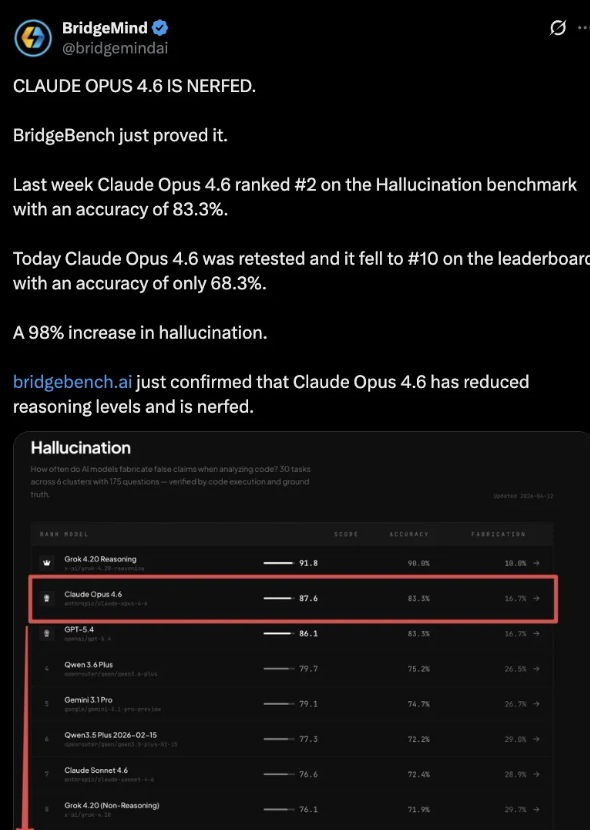
Even though the methodology was later criticized, the narrative stuck:
Claude is getting dumber.
People even coined a term — AI shrinkflation. Same price, diluted product.
In other words, users felt like they were getting a “kids’ meal.”
The three bugs explained
Silent downgrade of reasoning level
On March 4, Claude Code’s default reasoning level was lowered from “high” to “medium” due to latency concerns.
But the UI still showed “high.”
Users thought they were using full power — but actually got a downgraded version.
This lasted over a month before being rolled back.
Gets dumber the longer you chat
On March 26, a caching optimization was introduced:
- Intended: clear old reasoning after 1 hour of inactivity
- Actual: due to a bug, it cleared every single turn
Résultat :
- Claude kept working but forgot its own goals
- Symptoms: forgetfulness, repetition, chaotic tool use
Worse:
Because reasoning was constantly wiped, cache never hit → token usage skyrocketed.
It took 15 days to fix.
One prompt line crushed output quality
On April 16, a system instruction was added:
- Max 25 words between tool calls
- Final reply limited to 100 words
Impact:
- Opus 4.6 and 4.7 both dropped ~3% performance
- Rolled back after 4 days
April: a Series of Self-Inflicted Issues
Looking at the timeline, April wasn’t just bugs — it was a series of questionable moves.
April 4 — Blocking third-party tools
Anthropic blocked tools like OpenClaw from using Pro/Max subscriptions.
Want to keep using them? Switch to API billing.
April 21 — Quiet pricing changes
Claude Code was removed from the Pro plan page.
Support docs changed from:
- “Pro or Max” → “Max only”
After backlash, Head of Growth Amol Avasare claimed it was just a 2% A/B test.
Problem: the change was site-wide.
It got rolled back within hours.
Pricing reality
- Pro: $20/month → $240/year
- Max 5x: $100/month → $1200/year (5× increase)
- Max 20x: $2400/year (10× increase)
No middle tier.
April 23 — Postmortem and “compensation”
The compensation? Reset usage quotas.
Some users pointed out:
That had already happened during the Opus 4.7 release.
So this “compensation” was basically just a normal cycle reset.
Users aren’t buying it
Reactions are split.
Some say:
- Bugs happen
- The postmortem is transparent
- Boris Cherny actively responded on Hacker News
Others focus on a different issue:
Silence for two months
- No official communication
- Only scattered replies on X
- No consistent messaging
Suspicion about “cache optimization”
Some believe the timing (aligned with cache expiration) suggests:
Not latency optimization — but cost reduction.
A/B testing backlash
Different users received different product configurations silently.
Trust took another hit.
Migration is already happening
One interesting trend on Hacker News:
People sharing their “migration stories.”
Some said they subconsciously switched to Codex back in February — only now realizing Claude’s decline may have pushed them.
Others claim GPT-5.4 already outperformed Opus 4.6.
Some are supplementing with MiniMax:
- $40 → 4500 messages per 5-hour cycle
- Full reasoning visibility
The landscape has changed
Six months ago, “use Claude for coding” was almost consensus.
Now:
- Codex reportedly has 4 million active users
- GPT-5.5 focuses on coding + computer operation
- OpenAI staff even describe it as a “chief of staff” model
Claude didn’t necessarily get worse.
Others got better — and Claude stumbled at the worst possible moment.
The window is shrinking
Anthropic now has less time than before to:
- Fix bugs
- Rebuild trust
Meanwhile:
- GPT-5.5 is already out
- DeepSeek V4 is ready
And people are waiting:
Gemini, your move.

