
DeepSeek V4, qui a fait attendre le monde entier avec impatience jusqu’en avril, est enfin arrivé !
C'est tout à l'heure que DeepSeek V4 est enfin arrivé !
Aujourd’hui, DeepSeek, ce modèle qui, à lui seul, a autrefois brisé la domination des modèles à code source fermé et prouvé que DeepSeek commence à publier des mises à jour fréquentes afin de faire évoluer la dynamique du secteur, a officiellement annoncé aux développeurs du monde entier la sortie de la version préliminaire de la série DeepSeek-V4 —
L'ère des contextes civils à l'échelle du million (1M Context) est désormais une réalité, marquant un nouveau sommet en matière de capacités des agents open source, de connaissance du monde et de performances de raisonnement.
DeepSeek V4 s'est une nouvelle fois imposé comme leader en Chine et dans le domaine de l'open source, reflétant ainsi l'ascension fulgurante que nous avons observée depuis Qwen 3.6 a repoussé les limites.
Le rapport technique de V4 a également été publié au même moment.

Adresse de l'article : https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf
Présentation des modèles DeepSeek V4 : V4-Pro vs V4-Flash
DeepSeek V4-Pro : caractéristiques techniques du modèle phare
La série DeepSeek-V4 comprend deux versions : le DeepSeek-V4-Pro, véritable monstre de performances, avec 1,6 T de paramètres totaux et 49 milliards de paramètres activés.
DeepSeek V4-Flash : une version efficace et économique
DeepSeek-V4-Flash est spécialement conçu pour offrir un rendement élevé et une grande rentabilité, avec un total de 284 milliards de paramètres et 13 milliards de paramètres activés.
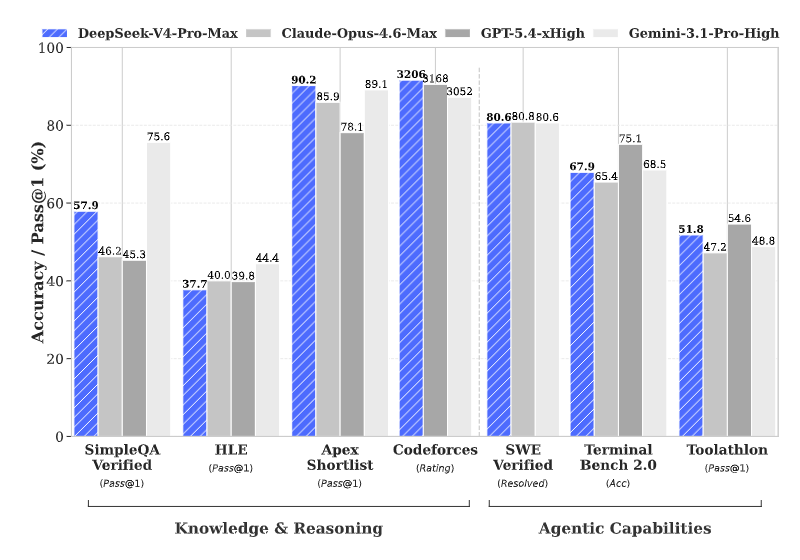
On peut affirmer que DeepSeek-V4-Pro a atteint un nouveau sommet parmi les modèles open source, se situant au même niveau que les meilleurs modèles propriétaires au monde.
Performances de DeepSeek V4-Pro : agent, base de connaissances et raisonnement
Progrès majeurs en matière de capacités des agents DeepSeek V4
Tout d'abord, V4-Pro a réalisé une avancée majeure en matière de capacités des agents, et son Codage agentique level occupe sans conteste la première place dans le monde de l'open source.
Les retours d'expérience issus des tests montrent que son expérience de codage a déjà surpassé celle de Sonnet 4.5, et que la qualité de ses prestations est en passe de rattraper celle de Opus 4.6 (mode « sans réfléchir »). C'est désormais devenu le modèle privilégié pour la programmation interne des agents au sein de l'entreprise.
Performances de DeepSeek V4 au benchmark « World Knowledge »
Deuxièmement, elle dispose d'un vaste réservoir de connaissances sur le monde.
En matière d'évaluation des connaissances, V4-Pro devance nettement les produits open source similaires, et l'écart avec la référence propriétaire Gemini-Pro-3.1 s'est réduit à une marge très faible.
Capacités de raisonnement et compétences en sciences, technologie, ingénierie et mathématiques (STEM) de DeepSeek V4
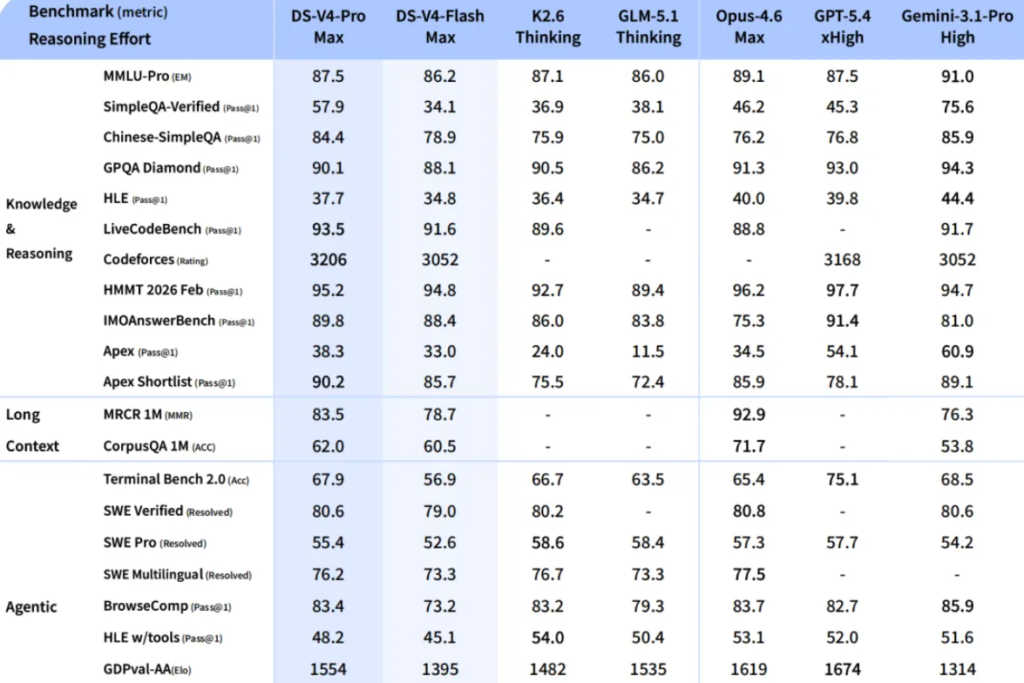
De plus, il offre des performances de haut niveau en matière de raisonnement logique.
En des domaines pointus tels que les mathématiques et les STIM, ainsi que dans le domaine de la programmation compétitive de haut niveau, V4-Pro domine non seulement la communauté open source, mais dispose déjà d'une réelle compétitivité sur le terrain pour rivaliser avec les modèles propriétaires les plus performants au monde.
Innovations architecturales de DeepSeek V4 : CSA, HCA et mHC
Ces deux modèles, qui permettent d'avoir une vue d'ensemble du domaine, s'appuient sur les “ trois grandes compétences ” de la technologie sous-jacente :
Attention hybride dans DeepSeek V4 (CSA + HCA)
DeepSeek-V4 n'a pas simplement augmenté ses investissements en matériel, mais a conçu de manière innovante une architecture d'attention hybride.
La méthode « Compressed Sparse Attention » (CSA) compresse le cache KV selon la dimension des tokens et la combine avec l'attention clairsemée DSA ; la méthode « Heavy Compressed Attention » (HCA) effectue une compression encore plus poussée afin de conserver un calcul dense.
Cette stratégie dite de “ combinaison de mots longs et courts ” réduit considérablement les besoins en calcul et en mémoire lorsque le modèle traite un contexte de plusieurs millions de mots.
Hyper-connexion contrainte par le manifold (mHC) dans DeepSeek V4
Afin d'améliorer la stabilité de la propagation du signal et de renforcer la puissance expressive du modèle, V4 introduit la structure mHC, qui améliore la connexion résiduelle traditionnelle.
Optimiseur Muon dans l'entraînement de DeepSeek V4
Le nouvel optimiseur Muon fait son apparition : il permet non seulement d'accélérer la convergence du processus d'apprentissage, mais aussi de le rendre plus stable.
Ce sont précisément ces innovations structurelles qui permettent à DeepSeek-V4 de réaliser un bond en avant qualitatif en matière d'efficacité d'inférence.
Dans le scénario extrême d'un contexte d'un million de tokens, le calcul d'inférence par token de DeepSeek-V4-Pro ne représente que 271 TP3T par rapport à la génération précédente, et l'utilisation du cache KV est réduite à un niveau étonnant de 101 TP3T.
Performances de DeepSeek V4-Flash : vitesse, coût et cas d'utilisation
Par rapport à la version Pro, la version Flash constitue un choix plus rapide, plus efficace et plus économique.
Comparaison entre DeepSeek V4-Flash Reasoning et la version Pro
Bien qu'il soit légèrement moins performant que la version Pro en termes de richesse des connaissances sur le monde, DeepSeek-V4-Flash conserve un niveau de raisonnement logique proche de celui-ci.
Avantages de l'API DeepSeek V4 en termes de coût et d'efficacité
Grâce à une échelle de paramètres et à un mécanisme d'activation plus rationalisés, il permet aux utilisateurs de bénéficier d'un accès à l'API plus réactif et moins coûteux.
Différences de performances des tâches des agents DeepSeek V4
Pour les tâches de base de l'Agent, V4-Flash offre des performances quasi identiques à celles de la version Pro, mais face à des tâches extrêmement complexes, il reste encore une marge de progression.
Percée de DeepSeek V4 en matière de contexte long : 1 million de tokens devient la norme
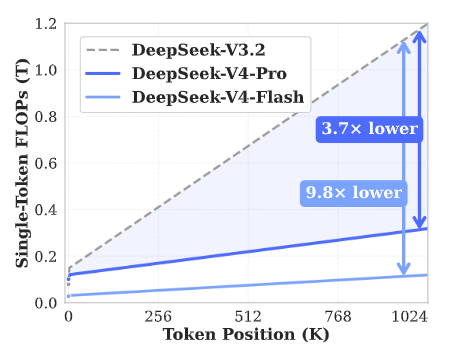
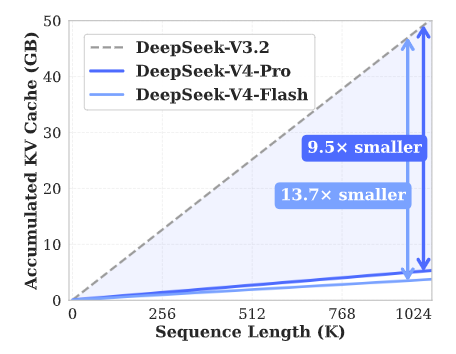
DeepSeek-V4 introduit un mécanisme d'attention révolutionnaire.
Grâce à une compression efficace au niveau des tokens et à l'intégration de la technologie d'attention clairsemée DSA (DeepSeek Sparse Attention), il offre des capacités de traitement des textes longs parmi les meilleures au monde.
DeepSeek V4 avec un contexte de 1 million de caractères comme configuration par défaut
À compter d'aujourd'hui, le contexte ultra-long de 1M (1 million de jetons) deviendra la configuration par défaut des services officiels de DeepSeek.
DeepSeek V4 par rapport aux modèles précédents : mémoire et puissance de calcul
Cette innovation réduit considérablement la dépendance vis-à-vis des ressources informatiques et de la mémoire.
Évolution des capacités de calcul et de mémoire de DeepSeek-V4 et DeepSeek-V3.2 en fonction de la longueur du contexte
Optimisation de l'agent DeepSeek V4 et intégration dans l'écosystème
Intégration de DeepSeek V4 aux frameworks d'agents
DeepSeek-V4 a mis en œuvre l'adaptation profonde pour les principaux écosystèmes d'agents tels que Claude Code, OpenClaw, OpenCode et CodeBuddy.
Cas d'utilisation de DeepSeek V4 : génération de code et de documents
Dans des contextes tels que l'écriture de code et la génération automatisée de documents, son efficacité en termes de production a été considérablement améliorée.
Exemple de diapositives PPT générées automatiquement par V4-Pro dans le cadre d'une architecture Agent spécifique
Mise à jour de l'API DeepSeek V4 et guide de migration des modèles
Comment utiliser l'API DeepSeek V4 (configuration de model_name)
Pour les développeurs, la bonne nouvelle, c'est que l'API est déjà disponible en ligne depuis ce moment-là !
Il vous suffit simplement de modifier « model_name » pour accéder à ces deux nouveaux modèles phares :
- Performances : deepseek-v4-pro
- Efficacité : deepseek-v4-flash
Calendrier de suppression progressive du modèle DeepSeek V4
Rappel important : les noms de modèles d'origine « deepseek-chat » et « deepseek-reasoner » serviront d'alias transitoires pour la version 4, mais ces deux anciens noms seront officiellement supprimés le 24 juillet 2026.
Aperçu du document technique sur DeepSeek V4
Explication du mécanisme de compression CSA de DeepSeek V4
Dans V4-Pro, le taux de compression du CSA est de 4. Le cache KV, qui regroupe 4 jetons, est fusionné en une seule entrée.
Stratégie de compression globale HCA de DeepSeek V4
Le mode HCA emprunte une autre voie. Le taux de compression est porté à 128, ce qui est bien plus agressif que le mode CSA.
Conception d'un modèle hybride DeepSeek V4 basé sur l'attention collaborative
Ces deux mécanismes sont superposés en alternance. Le CSA assure la recherche fine, tandis que le HCA se charge de la perception globale.
Innovations en matière d'apprentissage de DeepSeek V4 : Muon, MoE et la distillation
Optimisation de la stabilité des mHC avec DeepSeek V4
La méthode mHC impose des contraintes à la matrice de mappage résiduelle afin d'éviter toute divergence dans les réseaux profonds.
Optimiseur DeepSeek V4 Muon et astuces d'entraînement
Le principe fondamental de Muon réside dans l'orthogonalisation de la quantité de mouvement gradient.
DeepSeek V4, MegaMoE et accélération du système
V4 open-source MegaMoE, fusionnant la communication et le calcul au sein d'un seul noyau de pipeline.
DeepSeek V4 : distillation OPD et modèle de récompense GRM
V4 utilise la distillation « on-policy » et introduit un modèle de récompense génératif pour l'optimisation conjointe.
Pourquoi DeepSeek V4 est-il important pour l'IA open source ?
De l'essor fulgurant de la version V3 à la révolution en matière d'efficacité de la version V4, DeepSeek a toujours tenu à partager avec la communauté les technologies les plus pointues via l'open source.
Le lancement de DeepSeek-V4 ne représente pas seulement un bond en avant en termes de paramètres techniques, mais constitue également une réponse forte à l'évolution de l'écosystème de l'IA, s'imposant avec force face aux remous qui agitent le secteur, tels que le Fuite concernant « Anthropic Mythos ».
- Contexte long de plusieurs millions
- Systèmes d'agents hautement performants
Cela prouve que, grâce à l'innovation architecturale, nous pouvons réduire considérablement le seuil d'accès aux grands modèles sans compromettre les performances.
Vous pouvez dès à présent découvrir la nouvelle expérience contextuelle 1M dans l'application officielle ou sur chat.deepseek.com.
Ce n'est pas simplement une fenêtre de discussion. C'est un “ deuxième cerveau ” capable de contenir une encyclopédie entière et de comprendre la logique de dizaines de milliers de lignes de code.
Référence
https://huggingface.co/collections/deepseek-ai/deepseek-v4
https://modelscope.cn/collections/deepseek-ai/DeepSeek-V4
https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf

