
Claude Opus 4.7 La pensée adaptative est un système dans lequel le modèle décide automatiquement de l'effort de raisonnement à déployer en fonction de la complexité de la tâche. Il remplace les contrôles manuels de “réflexion étendue” par une allocation dynamique, visant à équilibrer la vitesse, le coût et la précision. Bien que cela améliore l'efficacité des tâches structurées telles que le codage, cela réduit le contrôle de l'utilisateur et peut conduire à des performances incohérentes dans les flux de travail longs ou complexes.
Source : Documentation officielle de Claude Opus 4.7
Qu'est-ce que la pensée adaptative dans Claude Opus 4.7 ?
La pensée adaptative est un cadre de raisonnement dans lequel le modèle ajuste dynamiquement la profondeur avec laquelle il traite une demande.
Au lieu d'imposer un mode de “réflexion profonde” fixe, le modèle :
- Utilise un raisonnement minimal pour les requêtes simples
- Attribue plus de jetons pour les tâches complexes
- Décide automatiquement sans intervention de l'utilisateur
Concrètement, cela signifie que
- Des réponses plus rapides pour les tâches de base
- Raisonnement potentiellement solide pour les problèmes complexes
- Pas de cohérence garantie dans l'application du raisonnement
Du point de vue de la conception du système, il s'agit d'un changement par rapport à l'ancien système de gestion de l'information. inférence contrôlée par l'utilisateur → inférence optimisée par le modèle.
En quoi est-elle différente de la pensée élargie ?
| Fonctionnalité | Réflexion approfondie (4.6) | Pensée adaptative (4.7) |
|---|---|---|
| Contrôle | Manuel | Automatique |
| Cohérence | Haut | Variable |
| Vitesse | Plus lent | Plus rapide en moyenne |
| Prévisibilité des coûts | Haut | Plus bas |
| Transparence | Raisonnement complet visible | Résumé du raisonnement |
La différence essentielle est le contrôle.
La pensée élargie a permis aux utilisateurs de obliger à un raisonnement approfondi.
La pensée adaptative suppose que le modèle peut décider mieux que l'utilisateur.
C'est là que commencent la plupart des frictions dans le monde réel.
Pourquoi la pensée adaptative semble-t-elle incohérente ?
Sur la base d'évaluations de flux de travail réels pour des tâches de codage, d'écriture et de raisonnement à long terme, l'incohérence provient de trois facteurs :
1. Mauvaise classification de la complexité
Le modèle traite parfois des tâches complexes comme des tâches simples.
Résultat :
- Réponses superficielles
- Étapes de raisonnement manquantes
2. Dégradation de la longueur du contexte
En des conversations longues avec des contextes étendus, La profondeur du raisonnement diminue souvent avec le temps.
Modèle observé :
- Messages précoces → raisonnement plus approfondi
- Messages plus tardifs → réponses plus rapides et moins profondes
Cela suggère que le modèle optimise l'efficacité au fur et à mesure que le contexte s'accroît.
3. Compression de la sortie
Le raisonnement est résumé au lieu d'être exposé en détail.
Effet :
- J'ai l'impression de moins réfléchir
- Plus difficile de déboguer ou de valider la logique
Pourquoi la pensée adaptative cesse-t-elle parfois de se déclencher complètement ?
Dans les conversations prolongées, la pensée adaptative peut non seulement réduire la profondeur, mais aussi cesser complètement de se déclencher.
Comportement observé :
- Conversation précoce → raisonnement activé
- Conversation ultérieure → réponses directes sans phase de raisonnement
Il ne s'agit pas d'une simple optimisation. Il s'agit d'une suggestion :
- Seuils internes d'activation du raisonnement
- Suppression possible en fonction de la longueur du contexte
Implication :
Pour les flux de travail de longue durée, la fiabilité du raisonnement n'est pas seulement plus faible, elle peut disparaître.
Étude de cas 1 : Décomposition d'une session de codage longue
Contexte :
Développeur travaillant sur un session de débogage en plusieurs étapes (20+ message thread)
Problème :
Les premières réponses étaient détaillées et méthodiques. Les réponses ultérieures sautent des étapes.
Test :
- Même bug que le prompt testé :
- Une nouvelle conversation
- Longue conversation
Résultats :
- Fresh chat : raisonnement complet, débogage étape par étape
- Long fil : réponses directes avec étapes logiques manquantes
Principaux enseignements :
La pensée adaptative se dégrade dans les contextes longs.
Il privilégie la rapidité à la profondeur lorsque la durée de la conversation augmente.
Étude de cas n° 2 : baisse de la qualité de la génération de contenu
Contexte :
Rédacteur générant du contenu de blog de longue durée
Problème :
La production est devenue plus générique au fil du temps
Test :
- Même consigne d'écriture avec :
- Invite structurée forcée
- Question ouverte
Résultats :
- Invitation structurée : qualité maintenue
- Open-ended : sortie superficielle, templée
Principaux enseignements :
La pensée adaptative sous-estime la complexité des tâches créatives.
La structure explicite améliore la profondeur du raisonnement.
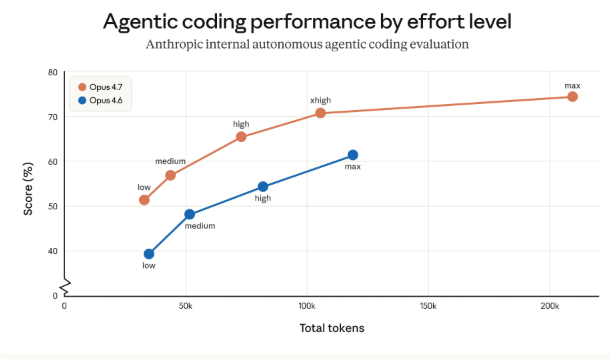
Étude de cas n° 3 : performances de codage de l'entreprise (données de référence)
Contexte :
Évaluation des tâches complexes d'ingénierie logicielle
Ce qui a été testé :
- Détection des bogues
- Raisonnement sur le code
- Résolution de problèmes en plusieurs étapes
Résultats :
- 3× plus de tâches de production résolues par rapport à la version précédente
- 10%+ amélioration du rappel de la détection des problèmes
- 21% Moins d'erreurs de raisonnement dans l'AQ basée sur des documents
Principaux enseignements :
La pensée adaptative est la plus performante dans les cas suivants
- Environnements structurés
- Des tâches clairement définies
- Des flux de travail mesurables
Il se bat davantage en :
- Raisonnement ouvert
- Longs contextes conversationnels
Pourquoi les indices de référence s'améliorent, mais l'utilisation réelle se détériore
L'Opus 4.7 de Claude affiche une forte progression des indices de référence :
- Plus de tâches résolues
- Un rappel plus important
- Moins d'erreurs
Cependant, l'utilisation en situation réelle semble souvent moins fiable.
Raison :
- Les repères sont courts, structurés et contrôlés
- Les flux de travail réels sont longs, ambigus et itératifs.
La pensée adaptative est la plus performante dans le premier cas, mais elle a du mal dans le second.
Cela crée un écart de perception :
Capacité plus élevée, mais fiabilité perçue plus faible.
Quand la pensée adaptative est-elle la plus efficace ?
La pensée adaptative donne de bons résultats lorsque
1. Les tâches sont clairement définies
- Problèmes de codification
- Analyse des données
- Requêtes structurées
2. Le contexte est court ou moyen
- Invites à tour de rôle
- Flux de travail courts
3. Les critères de sortie sont explicites
- Instructions étape par étape
- Des contraintes claires
Quand échoue-t-il ?
1. Longues conversations
La profondeur du raisonnement diminue avec le temps.
2. Tâches ambiguës
Le modèle propose par défaut des réponses peu profondes.
3. Raisonnement à enjeux élevés
L'absence de contrôle crée des risques :
- Étapes manquantes
- Hypothèses non vérifiées
Le vrai problème : la perte de prévisibilité et de confiance
Le plus gros problème n'est pas seulement l'incohérence.
C'est la perte de confiance.
Les utilisateurs ne peuvent plus faire de prévisions fiables :
- Quand le modèle réfléchit en profondeur
- Quand le raccourci sera fait
Cela crée un nouveau mode de défaillance :
Il ne s'agit pas de mauvaises réponses, mais d'un comportement de raisonnement imprévisible.
Comment améliorer les résultats grâce à la pensée adaptative
D'après les tests effectués, ces stratégies améliorent systématiquement la production :
1. Structure des forces
Au lieu de :
“Expliquez ce problème”
Utiliser :
“Décomposer en 5 étapes et expliquer chacune d'entre elles”
2. Réinitialiser fréquemment le contexte
Démarrer une nouvelle conversation pour :
- Tâches de raisonnement complexes
- Résultats critiques
3. Spécifier explicitement l'effort (API)
Si vous utilisez l'API :
- Utiliser des paramètres d'effort plus élevés
- Combiner avec des instructions pas à pas
4. Demander des résultats de raisonnement
Exemple d'invite :
“Montrez votre raisonnement avant la réponse finale”
Cela permet d'accroître la cohérence de la profondeur.
La pensée adaptative par rapport aux autres modèles de raisonnement de l'IA
| Modèle | Contrôle du raisonnement | La force | Faiblesse |
|---|---|---|---|
| Claude Opus 4.7 | Automatique | Efficacité, codification | Incohérence |
| Réflexion approfondie de type GPT | Contrôlé par l'utilisateur | Fiabilité | Plus lent |
| Systèmes hybrides | Semi-contrôlé | Équilibre | Complexité |
Conclusion :
- Pensée adaptative = optimisation de l'échelle
- Commande manuelle = optimisée pour la précision
Faut-il utiliser Claude Opus 4.7 ?
Utilisez-le si vous :
- Besoin d'un codage rapide et de haute qualité
- Travailler avec des tâches structurées
- Privilégier l'efficacité au contrôle
Évitez de vous y fier uniquement si vous :
- Nécessité d'un raisonnement approfondi et cohérent
- Travailler dans des flux de travail longs et complexes
- Exiger une transparence totale
FAQ : Claude Opus 4.7 Pensée adaptative
Quelle est la différence entre la pensée adaptative et la pensée élargie ?
La pensée adaptative décide automatiquement du niveau de raisonnement à appliquer en fonction de la complexité de la tâche, tandis que la pensée étendue permet aux utilisateurs de forcer manuellement un raisonnement plus approfondi. La différence essentielle est le contrôle : La pensée adaptative est pilotée par un modèle, tandis que la pensée étendue est contrôlée par l'utilisateur.
Pourquoi ne puis-je plus passer manuellement au raisonnement profond dans Claude 4.7 ?
Claude 4.7 est conçu pour optimiser automatiquement le raisonnement. Au lieu de proposer un basculement manuel, le modèle décide quand un raisonnement plus approfondi est nécessaire. Cela améliore l'efficacité mais supprime le contrôle explicite de l'utilisateur.
Pourquoi la pensée adaptative diminue-t-elle ou s'arrête-t-elle lors de longues conversations ?
À mesure que la longueur du contexte augmente, le modèle tend à réduire la profondeur du raisonnement afin de gérer les problèmes d'accès à l'information. coût de calcul et la vitesse de réaction. Dans la pratique, cela conduit à :
- Raisonnement moins détaillé
- Réponses plus rapides mais moins profondes
La pensée adaptative améliore-t-elle réellement les résultats ou permet-elle simplement d'économiser des jetons ?
Il fait les deux.
- Dans les tâches structurées, il améliore l'efficacité et peut maintenir ou améliorer la précision.
- Dans les tâches complexes ou à contexte long, il peut donner la priorité à l'économie de jetons plutôt qu'à un raisonnement plus approfondi
L'efficacité dépend du cas d'utilisation.
Pourquoi la même question complexe fait-elle l'objet d'un meilleur raisonnement dans un nouveau chat que dans un ancien ?
Les nouveaux chats ont un contexte plus court et un budget de calcul plus important. Dans les conversations plus longues, le modèle tend à optimiser la vitesse et l'efficacité, ce qui peut réduire la profondeur du raisonnement pour une même question.
Claude 4.7 pense-t-il moins parce qu'il ne montre pas son raisonnement ?
Non. Le modèle effectue toujours le raisonnement en interne, mais il n'affiche plus les chaînes de raisonnement complètes par défaut. La différence se situe au niveau de la visibilité des résultats, pas nécessairement au niveau de la capacité de raisonnement.
La réflexion est-elle supprimée, cachée ou résumée ?
Dans la plupart des cas, il s'agit d'un résumé. Le processus de raisonnement complet existe toujours en interne, mais le modèle produit une version comprimée au lieu de la chaîne de pensée complète.
Dois-je me fier à la pensée résumée ou à la pensée brute dans les flux de travail de Claude Code ou de l'agent ?
Cela dépend de votre cas d'utilisation :
- Utiliser la pensée résumée pour plus de rapidité et de lisibilité
- Utiliser le raisonnement brut ou élargi lors du débogage, de la validation de la logique ou de la construction d'agents.
Pour les flux de travail critiques, un raisonnement plus transparent est plus sûr.
Pourquoi certains utilisateurs disent que Claude 4.7 est meilleur alors que d'autres disent qu'il fait plus d'erreurs ?
Claude 4.7 a un plafond de performance plus élevé mais une cohérence plus faible :
- Plus fort dans les tâches structurées et bien définies
- Moins prévisible dans les scénarios ouverts ou à long terme
Cela crée des expériences mixtes pour les utilisateurs.
Comment puis-je utiliser le paramètre “effort” de l'API pour imiter la pensée profonde ?
Augmenter la profondeur du raisonnement :
- Utiliser des paramètres d'effort plus élevés (par exemple, moyen ou élevé)
- Combinez avec des questions structurées telles que
- “Expliquer étape par étape”
- “Montrez votre raisonnement avant la réponse”
Remarque : l'effort influence le comportement mais ne reproduit pas entièrement la réflexion profonde forcée.
Dois-je utiliser Claude 4.7 ou revenir à 4.6 pour plus de stabilité ?
Choisissez en fonction de vos priorités :
- Utilisez la version 4.7 si vous le souhaitez :
- Performances accrues en matière de codage et de tâches complexes
- Une meilleure efficacité
- Utilisez la version 4.6 si nécessaire :
- Un raisonnement plus cohérent
- Un meilleur contrôle des sorties
En bref : 4,7 privilégie la performance, 4,6 privilégie la prévisibilité.
Aperçu final
La pensée adaptative est une évolution vers l'automatisation, et non vers le contrôle de précision. Elle améliore l'efficacité à grande échelle mais introduit de la variabilité. Le véritable avantage apparaît lorsque les utilisateurs adaptent leurs messages et leurs flux de travail pour guider le modèle, plutôt que de compter sur lui pour prendre des décisions correctes à chaque fois.
La pensée adaptative introduit un nouveau type de mode d'échec : non pas des réponses incorrectes, mais un comportement de raisonnement imprévisible.

