
Réponse courte :
Opus 4.6 offre actuellement une plus grande fiabilité, un coût plus faible et de meilleurs taux de réussite en une seule fois dans les flux de travail de codage du monde réel, tandis que Opus 4.7 présente un potentiel dans les tâches ouvertes, mais nécessite plus de réglages, des budgets de jetons plus élevés et plus de tentatives pour atteindre des résultats similaires.
Opus 4.7 vs Opus 4.6 : Performances réelles et tests de référence
La plupart des comparaisons entre Opus 4.7 et Opus 4.6 s'appuient sur des critères de référence contrôlés. Cependant, lorsque l'évaluation se fait dans le cadre de flux de travail de développement réels sur plusieurs jours, une image différente apparaît.
Lors d'une évaluation côte à côte de plusieurs jours utilisant des milliers d'interactions de codage réelles :
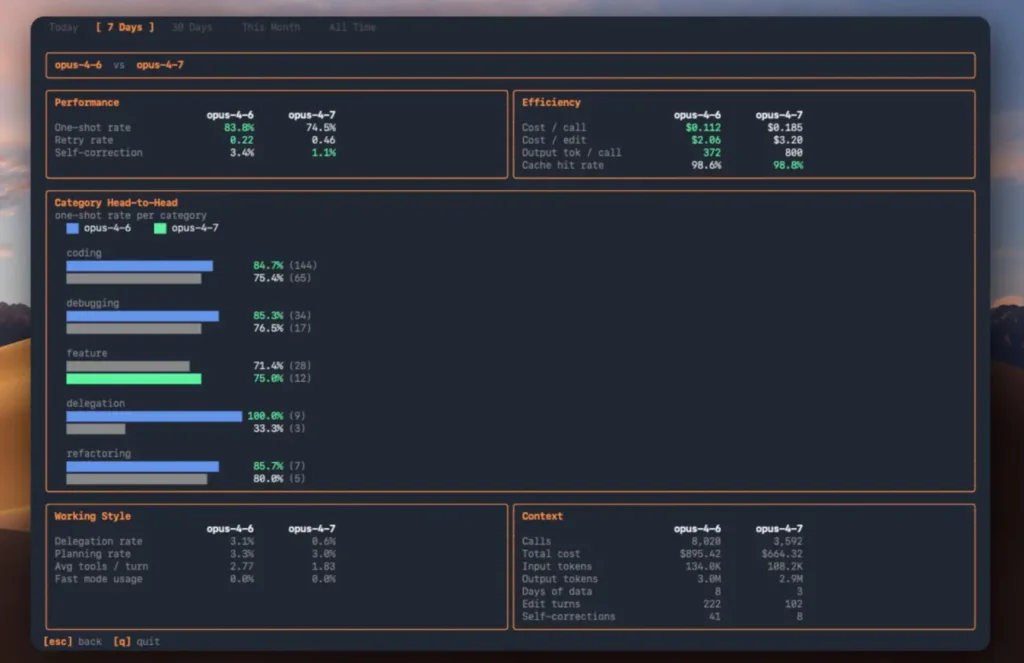
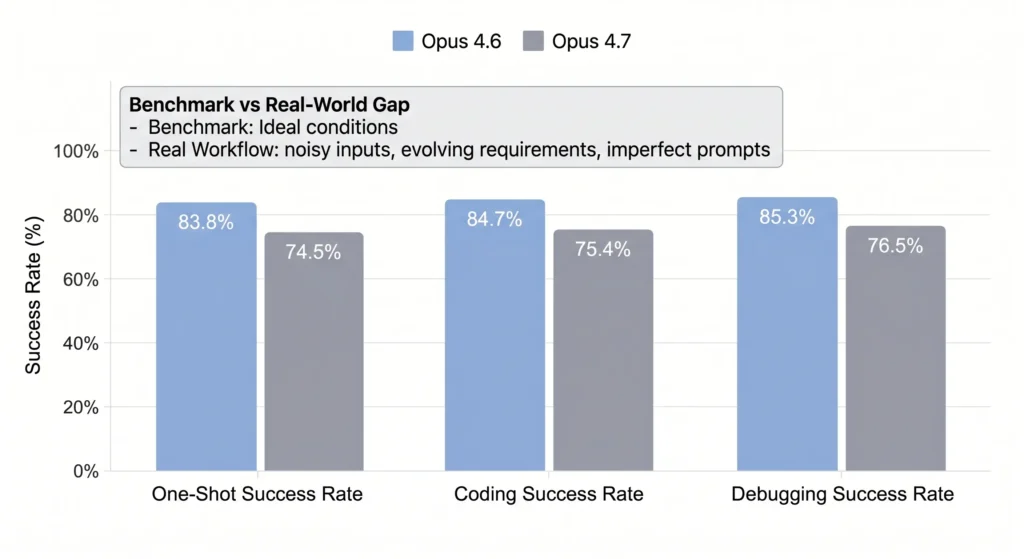
- Opus 4.6 réalisé 83,8% taux de réussite d'un seul coup
- L'Opus 4.7 est passé à 74.5%
- Le succès du débogage a diminué de 85,3% → 76,5%
- Le taux de réussite des tâches de codage est passé de 84,7% → 75,4%
Cette lacune met en évidence une distinction essentielle :
les gains de référence ne se traduisent pas nécessairement par une efficacité de la production.
Dans la pratique, les flux de travail réels introduisent du bruit - un contexte partiel, des exigences changeantes et des invites imparfaites. Dans ces conditions, Opus 4.6 s'avère plus indulgent et plus fiable.
Coût et efficacité des jetons : Pourquoi Opus 4.7 est-il nettement plus cher ?
L'une des différences les plus mesurables entre Opus 4.7 et Opus 4.6 est la rentabilité.
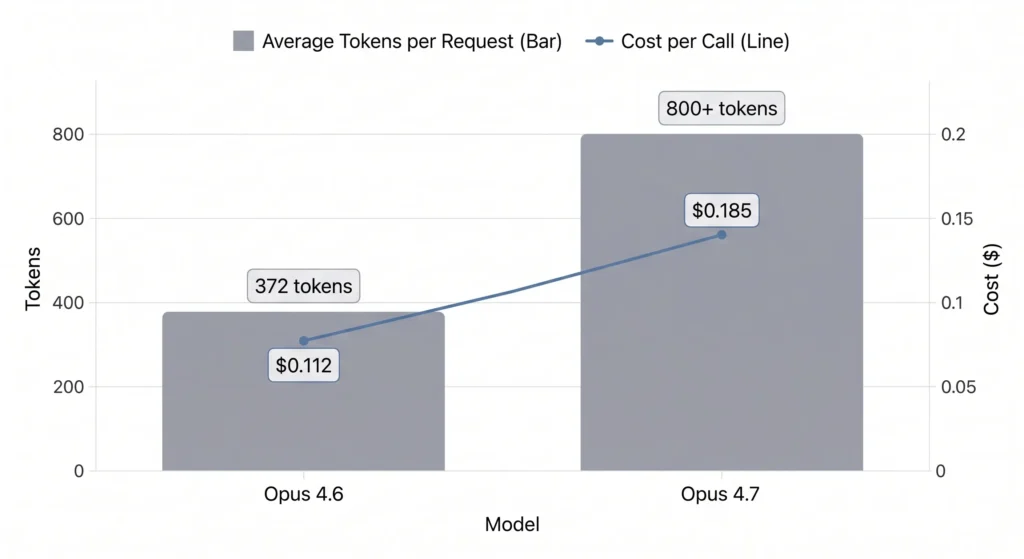
À travers des milliers d'appels API :
- Nombre moyen de jetons par demande :
- 4.6: 372
- 4.7: 800+
- Coût par appel :
- 4.6: $0.112
- 4.7: $0.185 (+65%)
Cette augmentation n'est pas seulement théorique, elle s'accentue rapidement en utilisation réelle.
Qu'est-ce qui motive l'augmentation des coûts ?
- Une plus grande verbosité
Les réponses sont beaucoup plus longues et comprennent souvent des raisonnements redondants. - Plus de tentatives nécessaires
Les sorties ratées entraînent des appels supplémentaires, ce qui multiplie les coûts. - Densité de signal plus faible
Un plus grand nombre de jetons ne signifie pas nécessairement de meilleures réponses.
Dans les environnements de production, cela crée un compromis clair :
Opus 4.7 est peut-être plus performant en théorie, mais Opus 4.6 est plus rentable par résultat positif.
Fiabilité et itération : Pourquoi Opus 4.6 gagne dans les flux de travail des développeurs
Au-delà des taux de réussite bruts, le coût des itérations est un facteur majeur de productivité.
Taux de réessai mesurés :
- 4.6: 0,22 tentatives par tâche
- 4.7: 0,46 tentatives par tâche (≈2x plus élevé)
Cela a des effets en cascade :
- Plus d'interruptions dans le flux de travail
- Charge cognitive accrue
- Dégradation du contexte sur plusieurs tours
Impact réel sur le flux de travail
Avant (Opus 4.6) :
- Forte probabilité d'obtenir un résultat utilisable dès la première tentative
- Cycles de correction minimaux
Après (Opus 4.7) :
- Nécessité plus fréquente d'affiner les messages-guides
- Risque plus élevé de résultats partiels ou incorrects
- Augmentation de l'interaction en va-et-vient
Le résultat est clair :
même de petites baisses de précision en une seule fois réduisent de manière significative la productivité globale.
Étude de cas : 3 jours d'évaluation du codage côte à côte
Mise en place
- Environnement : Tâches de développement dans le monde réel (pas de repères synthétiques)
- Durée de l'enquête :
- Opus 4.7 : 3 592 appels (3 jours)
- Opus 4.6 : 8 020 appels (8 jours)
- Outils : Claude Code + codeburn analytics
Comparaison des indicateurs clés
| Métrique | Opus 4.6 | Opus 4.7 |
|---|---|---|
| Succès d'un seul coup | 83.8% | 74.5% |
| Succès du codage | 84.7% | 75.4% |
| Débogage réussi | 85.3% | 76.5% |
| Tentatives par tâche | 0.22 | 0.46 |
| Jetons par appel | 372 | 800+ |
| Coût par appel | $0.112 | $0.185 |
Vue d'ensemble
Cet ensemble de données montre que :
- La régression des performances est mesurable et non anecdotique
- Les coûts augmentent alors que les taux de réussite diminuent
- La surcharge d'itération devient le goulot d'étranglement caché
Étude de cas : Développement de fonctionnalités et performances de débogage
Il est intéressant de noter que toutes les tâches ne présentent pas de régression.
En cours de développement :
- Opus 4.6 : 71,4% succès
- Opus 4.7 : 75% succès
Bien qu'elle soit basée sur un échantillon plus restreint, cette étude suggère :
- Opus 4.7 peut être plus performant dans :
- Tâches ouvertes
- Codage exploratoire
- Résolution créative de problèmes
Mais il a du mal à le faire :
- Débogage déterministe
- Logique de précision
- Exigences strictes en matière d'exactitude
Interprétation
Opus 4.7 est optimisé pour exploration, tandis que l'Opus 4.6 reste plus fort pour les exécution.
Étude de cas : Utilisation des outils et comportement des agents
Un autre résultat inattendu est le déclin de l'utilisation des outils et de la délégation :
- Outils par tour :
- 4.6: 2.77
- 4.7: 1.83
- Taux de délégation :
- 4.6: 3.1%
- 4.7: 0.6%
Pourquoi c'est important
Les flux de travail modernes de l'IA s'appuient sur :
- Appel d'outils
- Raisonnement en plusieurs étapes
- Délégation des sous-agents
La réduction de l'utilisation suggère :
- Moins de décomposition des problèmes
- Plus de réponses monolithiques
- Efficacité moindre au niveau du système
Ceci peut expliquer en partie cela :
- Augmentation de la verbosité
- Taux de réussite plus faibles
- Nombre de tentatives plus élevé
Sensibilité à la demande : Pourquoi Opus 4.7 nécessite une ré-optimisation
L'Opus 4.7 se comporte de manière plus littérale, ce qui est une constatation constante dans tous les tests.
Principales différences
Opus 4.6 :
- Détermine l'intention de l'utilisateur
- Complète les détails manquants
- Plus indulgent avec les messages vagues
Opus 4.7 :
- Respect strict des instructions
- Moins de raisonnement implicite
- Nécessite des messages-guides très structurés
Impact pratique
Les équipes qui migrent vers la version 4.7 sont confrontées :
- Coûts de la refonte rapide
- Réécriture de l'invite du système
- Réajustement du pipeline
Sans ces ajustements, les performances peuvent apparaître plus mauvaises qu'elles ne le sont en réalité.
Créativité ou précision : Compromis entre 4.7 et 4.6
Une autre tendance est observée pour l'ensemble des usages :
- Opus 4.6 :
- Plus intuitif
- Meilleur pour le brainstorming
- Un “sentiment créatif” plus fort”
- Opus 4.7 :
- Plus rigide
- Plus structuré
- Moins de variations stylistiques
Il en résulte un compromis évident :
| Cas d'utilisation | Meilleur modèle |
|---|---|
| Création littéraire | 4.6 |
| Remue-méninges | 4.6 |
| Pipelines structurés | 4.7 |
| Exploration ouverte | 4.7 |
Quand utiliser Opus 4.7 ou Opus 4.6 ?
Choisissez Opus 4.6 si vous en avez besoin :
- Grande précision en un coup
- Coût inférieur par tâche
- Débogage fiable
- Ingénierie rapide minimale
Choisissez Opus 4.7 si vous en avez besoin :
- Raisonnement complexe en plusieurs étapes
- Génération ouverte
- Respect strict de l'instruction
- Contrôle des pipelines
FAQ : Opus 4.7 vs Opus 4.6
Opus 4.7 est-il réellement meilleur qu'Opus 4.6 ?
Pas de façon constante. Il est plus performant dans certaines tâches ouvertes, mais moins performant dans la fiabilité du codage et le rapport coût-efficacité.
Pourquoi Opus 4.7 utilise-t-il plus de jetons ?
Elle produit des réponses plus longues et plus détaillées et nécessite souvent un plus grand nombre de tentatives, ce qui augmente la consommation totale de jetons.
L'Opus 4.7 hallucine-t-il davantage ?
Dans les tâches sensibles à la précision (comme le raisonnement numérique), il montre plus d'erreurs que les 4,6 dans les flux de travail réels.
Dois-je passer d'Opus 4.6 à 4.7 ?
Seulement si vous êtes prêt à le faire :
- Ré-optimiser les messages-guides
- Accepter des coûts plus élevés
- Troquer la fiabilité contre la flexibilité
Pourquoi l'Opus 4.7 semble-t-il plus “rigide” ?
Il suit les instructions plus littéralement et est moins enclin à déduire le contexte manquant, ce qui le rend moins intuitif.
Les performances de référence sont-elles trompeuses ?
Oui. Les gains obtenus grâce à l'analyse comparative ne reflètent pas toujours la productivité réelle, en particulier dans les flux de travail itératifs.
Pourquoi les tentatives sont-elles plus nombreuses dans Opus 4.7 ?
Une moindre précision en une seule fois entraîne un plus grand nombre de cycles de correction, ce qui augmente le nombre de tentatives et les coûts.
Opus 4.7 est-il meilleur pour le codage ?
Dans son état actuel, il n'est pas adapté à la plupart des flux de travail. Il est moins performant pour le débogage et les tâches déterministes.
Opus 4.7 nécessite-t-il de nouvelles invites ?
Oui, il faut souvent des messages plus structurés et plus explicites pour obtenir des résultats optimaux.
Opus 4.7 est-il toujours en cours d'amélioration ?
Sur la base du comportement observé, il est probable qu'il nécessite davantage de réglages et d'optimisations pour atteindre son plein potentiel.
Verdict final
Opus 4.7 représente une évolution vers une IA plus structurée, qui suit les instructions, mais cette évolution s'accompagne de compromis.
Pour la plupart des flux de travail actuels :
- Opus 4.6 est plus efficace, plus fiable et plus rentable
- Opus 4.7 est plus expérimental, plus souple, mais moins prévisible.
L'essentiel n'est pas de savoir quel modèle est “meilleur”, mais plutôt de savoir ceci :
Le meilleur modèle est celui qui minimise les tentatives, les coûts et les frictions dans votre flux de travail réel, et non celui qui obtient les meilleurs résultats dans les tests de référence.

