
À l'instant, DeepSeek’s GitHub a commencé à publier des mises à jour régulières. Il a lancé et mis en open source un nouveau dépôt, Noyaux de tuiles, et a par la même occasion mis à jour le DeepEP référentiel, apportant DeepEP V2 en ligne. Cela fait moins d'une semaine que DeepSeek a discrètement mis à jour Mega MoE et Indexeur FP4 la dernière fois.
Noyaux de tuiles DeepSeek
Lien : https://github.com/deepseek-ai/TileKernels
D'après l'introduction, Noyaux de tuiles sont des noyaux GPU optimisés pour les opérations LLM, développés avec TileLang. TileLang est un langage spécifique à un domaine permettant d'exprimer des noyaux GPU hautement performants en Python, qui se caractérise notamment par une portabilité aisée, un développement agile et une optimisation automatique.
Les performances des “ Tile Kernels ” sont exceptionnelles. Comme l’a écrit DeepSeek lui-même : « La plupart des noyaux de ce projet frôlent déjà les limites de performance du matériel en termes d’intensité de calcul et de bande passante mémoire. Certains d’entre eux ont déjà été utilisés en interne dans des scénarios d’entraînement et d’inférence. Cependant, ils ne constituent pas encore des bonnes pratiques, et nous continuons à améliorer la qualité du code et la documentation. »
Le référentiel ne contient pas beaucoup d'informations introductives, mais entre les lignes, il “ dévoile ” déjà la voie de l'innovation architecturale qui sous-tend les modèles de nouvelle génération de DeepSeek, laissant entrevoir un bond en avant comparable à celui récemment Lancement en avant-première de Hy3.
Fonctionnalités des noyaux de tuiles DeepSeek
Voici quelques caractéristiques spécifiques des noyaux de tuiles :
Mécanisme de déclenchement : Sélection des k meilleurs experts et notation pour le routage par MoE
Acheminement MoE : Mise en correspondance des jetons avec les experts, fusion des opérations d'expansion et de réduction, et normalisation des poids
Quantification : Prend en charge la conversion FP8/FP4/E5M6 en modes « par token », « par bloc » et « par canal », et combine les opérations SwiGLU et de quantification
Transposer : Opérations de transposition par lots
Engramme : Noyaux de déclenchement d'engrammes, fusion de RMSNorm, propagation avant/arrière et réduction du gradient des poids
Hyperconnexion multiple : Noyaux d'hyperconnexion, notamment la normalisation de Sinkhorn et la technique « split/apply » pour le mixage
Modélisation : De haut niveau torch.autograd.Function enveloppes qui regroupent les noyaux sous-jacents en couches pouvant être entraînées (engram gate, mHC pipeline)
DeepSeek EPv2 : une version plus rapide d'EP prenant en charge Engram, PP et CP
Lien EPv2 : https://github.com/deepseek-ai/DeepEP/pull/605
Plus tôt dans la journée, DeepSeek a également publié la dernière version de EPv2, pour une livraison plus rapide parallélisme expert (EP) et la prise en charge de Engramme / parallélisme de pipeline (PP) / parallélisme de contexte (CP).
À mesure que le matériel, les réseaux et les architectures de modèles ont évolué parallèlement aux lancements rapides de nouveaux produits dans le secteur, tels que Qwen 3.6, La version précédente de DeepSeek, DeepEP V1, avait déjà accumulé trop de problèmes hérités du passé et trop de problèmes de performances.
Cette mise à jour restructure entièrement Parallélisme avancé. Par rapport à la version 1, elle ne nécessite qu’une fraction des ressources SM pour atteindre des performances exceptionnelles, tout en prenant en charge des applications à plus grande échelle mise à l'échelle (sur une seule machine) et évolutivité horizontale (sur différents ordinateurs).
Par ailleurs, DeepSeek a lancé une fonctionnalité expérimentale 0 SM séries présentées dans cette mise à jour, notamment 0 SM Engram, 0 Parallélisme du pipeline SM (PP), et 0 Parallélisme contextuel (CP) de SM Opérateurs de regroupement. Parallèlement, le backend a été remplacé par NVSHMEM vers le briquet Gin NCCL backend.
Nouvelles fonctionnalités de DeepSeek DeepEP V2
Voici quelques-unes des nouvelles fonctionnalités de DeepEP V2 :
Entièrement JIT
Backend de NCCL Gin :
Uniquement l'en-tête, extrêmement léger
Permet de réutiliser les communicateurs NCCL existants
EPv2 :
Il regroupe les API à haut débit et à faible latence au sein d'une interface unique, et adopte une toute nouvelle architecture GEMM.
Prend en charge des domaines de mise à l'échelle plus vastes, jusqu'à EP2048
Introduit un calcul analytique du nombre de SM et de QP, rendant ainsi le réglage automatique inutile
Continue à prendre en charge les deux Hybride mode et Direct mode
Pour les tâches d'entraînement plus anciennes de type V3, l'utilisation des SM diminue, passant de 24 à 4–6, tout en conservant des performances identiques, voire supérieures
0 SM Engram (avec RDMA)
0 SM PP (avec RDMA)
0 SM CP (avec Copy Engine)
Performances de DeepSeek DeepEP V2
Une fois la configuration de DeepSeek-V3, des tests ont été effectués avec la nouvelle version, en utilisant les paramètres suivants : 8 000 jetons par lot, 7168 dimension cachée, Les 8 meilleurs experts, Communiqué FP8, et Moissonneuse-batteuse BF16. Les résultats sont les suivants :
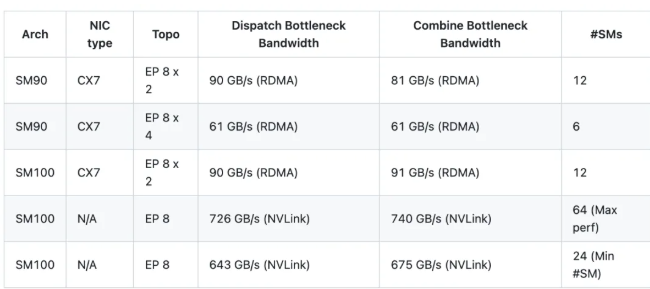
Remarque : les résultats indiqués correspondent à la bande passante logique. Par exemple, dans le cas de Épisode 8, partie 2, le 90 Go/s La bande passante inclut en effet le trafic entre les GPU locaux (rangs locaux).
Par rapport à la version V1, la version V2 atteint jusqu’à 1,3 fois les performances maximales, tout en économisant jusqu'à Utilisation des ressources SM × 4 — une optimisation essentielle pour rester compétitif dans un secteur dominé par des géants tels que Claude Opus 4.7.
Pour finir, juste un petit conseil pour DeepSeek : dépêchez-vous de sortir la version V4 Déjà. Tout le monde commence à s'impatienter.

