
Proprio ora, DeepSeek's GitHub ha iniziato ad aggiornarsi frequentemente. Ha lanciato e reso disponibile un nuovo repository, Gherigli di piastrelle, e allo stesso tempo ha aggiornato il ProfondoEP repository, portando DeepEP V2 online. È passata meno di una settimana da quando DeepSeek ha aggiornato in modo silenzioso Mega MoE e Indicizzatore FP4 l'ultima volta.
Kernel di piastrelle DeepSeek
Link: https://github.com/deepseek-ai/TileKernels
Secondo l'introduzione, Gherigli di piastrelle sono kernel per GPU ottimizzati per le operazioni LLM, costruiti con PiastrellaLang. TileLang è un linguaggio specifico per il dominio per esprimere kernel di GPU ad alte prestazioni in Python, con caratteristiche quali la facile portabilità, lo sviluppo agile e l'ottimizzazione automatica.
Le prestazioni dei kernel Tile sono estremamente elevate. Come ha scritto la stessa DeepSeek: “La maggior parte dei kernel di questo progetto sono già vicini al limite delle prestazioni hardware in termini di intensità di calcolo e larghezza di banda della memoria. Alcuni di essi sono già stati utilizzati internamente in scenari di addestramento e inferenza. Tuttavia, non rappresentano ancora le migliori pratiche e stiamo continuando a migliorare la qualità del codice e la documentazione”.”
Non ci sono molte informazioni introduttive nel repository, eppure tra le righe si “spoetizza” già il percorso di innovazione architettonica di fondo dei modelli di prossima generazione di DeepSeek, segnalando un salto paragonabile al recente Lancio in anteprima di Hy3.
Caratteristiche dei kernel di piastrelle DeepSeek
Ecco alcune caratteristiche specifiche di Tile Kernel:
Meccanismo di regolazione: Selezione degli esperti top-k e punteggio per il routing MoE
Instradamento del Ministero dell'Ambiente: Mappatura dei token agli esperti, fused expand/reduce e normalizzazione dei pesi
Quantizzazione: Supporta la conversione FP8/FP4/E5M6 in modalità per-token, per-blocco e per-canale e fonde SwiGLU + operazioni di quantizzazione
Trasposizione: Operazioni di trasposizione in batch
Engram: Engram gating kernel, fusione di RMSNorm, propagazione avanti/indietro e riduzione del peso-gradiente
Collettore HyperConnection: Kernel di iperconnessione, compresa la normalizzazione Sinkhorn e la suddivisione/applicazione per il mix
Modellazione: Alto livello torcia.autograd.funzione wrapper che combinano i kernel sottostanti in strati addestrabili (engram gate, mHC pipeline)
DeepSeek EPv2: EP più veloce con supporto per Engram, PP e CP
Collegamento EPv2: https://github.com/deepseek-ai/DeepEP/pull/605
All'inizio della giornata, DeepSeek ha rilasciato anche l'ultima versione di EPv2, consegnando più velocemente parallelismo esperto (EP) e il supporto per Engram / parallelismo della pipeline (PP) / parallelismo del contesto (CP).
L'evoluzione dell'hardware, delle reti e delle architetture dei modelli è avvenuta di pari passo con le rapide release del settore, come ad esempio Qwen 3.6, Il precedente DeepEP V1 di DeepSeek aveva già accumulato troppo bagaglio storico e troppi problemi di prestazioni.
Questo aggiornamento ristruttura completamente Parallelismo esperto. Rispetto alla V1, ha bisogno solo di una frazione delle risorse SM per raggiungere prestazioni estreme, supportando al tempo stesso una scala più ampia. scalabilità (all'interno di una singola macchina) e scalare (tra le macchine).
Inoltre, DeepSeek ha introdotto un sistema sperimentale di 0 SM in questo aggiornamento, tra cui 0 SM Engram, 0 Parallelismo della pipeline SM (PP), e 0 Parallelismo contestuale SM (CP) Operatori di raccolta. Allo stesso tempo, il backend è passato da NVSHMEM all'accendino NCCL Gin backend.
Nuove funzionalità in DeepSeek DeepEP V2
Ecco alcune delle nuove funzioni di DeepEP V2:
Completamente JIT
Backend NCCL Gin:
Solo testata, estremamente leggero
Possibilità di riutilizzare i comunicatori NCCL esistenti
EPv2:
Unifica le API ad alta velocità e a bassa latenza in un'unica interfaccia e adotta un nuovissimo layout GEMM.
Supporta domini di scala più grandi, fino a EP2048
Introduce il calcolo analitico del conteggio di SM e QP, per cui non è più necessario l'autotuning.
Continua a sostenere sia Ibrido e Diretto modalità
Per i compiti di formazione più vecchi, simili a quelli della V3, l'uso dell'SM scende da 24 a 4-6, mantenendo le stesse prestazioni, se non addirittura migliori
0 SM Engram (con RDMA)
0 SM PP (con RDMA)
0 SM CP (con Copy Engine)
Prestazioni di DeepSeek DeepEP V2
Seguendo la configurazione di DeepSeek-V3, I test sono stati eseguiti nella nuova versione con le impostazioni di 8K gettoni per lotto, 7168 dimensione nascosta, Top-8 degli esperti, Spedizione FP8, e Combinazione BF16. I risultati sono i seguenti:
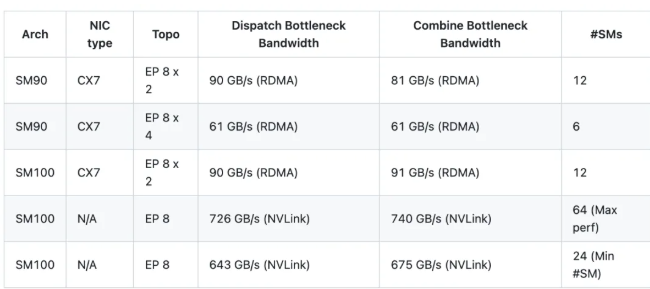
Nota: i risultati mostrati si riferiscono alla larghezza di banda logica. Ad esempio, nel caso di EP 8 x 2, il 90 GB/s La larghezza di banda include in realtà il traffico tra le GPU locali (ranghi locali).
Rispetto a V1, V2 raggiunge fino a 1,3 volte le prestazioni di picco, risparmiando fino a Utilizzo delle risorse SM 4× -Un'ottimizzazione cruciale per rimanere competitivi in un panorama dominato da pesi massimi quali Claude Opus 4.7.
Infine, un piccolo consiglio per DeepSeek: sbrigatevi a rilasciare V4 già. Tutti stanno diventando impazienti.

