
Hace un momento, DeepSeek's GitHub empezó a actualizarse con frecuencia. Puso en marcha un nuevo repositorio de código abierto, Núcleos de azulejos, y, al mismo tiempo, actualizó el DeepEP repositorio, aportando DeepEP V2 en línea. Ha pasado menos de una semana desde que DeepSeek actualizó silenciosamente Mega ME y Indexador FP4 la última vez.
Núcleos de azulejos DeepSeek
Enlace: https://github.com/deepseek-ai/TileKernels
Según la introducción, Núcleos de azulejos son kernels de GPU optimizados para operaciones LLM, construidos con TileLang. TileLang es un lenguaje específico para expresar kernels de GPU de alto rendimiento en Python, con características como la fácil portabilidad, el desarrollo ágil y la optimización automática.
El rendimiento de los Tile Kernels es extremadamente alto. Como escribió el propio DeepSeek: “La mayoría de los kernels de este proyecto ya están cerca del límite de rendimiento del hardware en términos de intensidad de cálculo y ancho de banda de memoria. Algunos de ellos ya se han utilizado internamente en escenarios de entrenamiento e inferencia. Sin embargo, aún no representan las mejores prácticas, y seguimos mejorando la calidad del código y la documentación.”
No hay mucha información introductoria en el repositorio, pero entre líneas ya “desvela” el camino de innovación arquitectónica subyacente de los modelos de próxima generación de DeepSeek, señalando un salto comparable al reciente Preestreno de Hy3.
Características de DeepSeek Tile Kernels
Éstas son algunas de las características específicas de los Tile Kernels:
Mecanismo de cierre: Selección y puntuación de expertos Top-k para el enrutamiento MoE
Enrutamiento MoE: Asignación de tokens a expertos, expansión/reducción fusionada y normalización de pesos
Cuantización: Admite la conversión FP8/FP4/E5M6 en los modos por token, por bloque y por canal, y fusiona las operaciones SwiGLU + cuantificación.
Transponer: Operaciones de transposición por lotes
Engram: Núcleos de engramación, fusión de RMSNorm, propagación hacia delante/atrás y reducción del gradiente de peso.
Hiperconexión de colectores: Núcleos de hiperconexión, incluida la normalización Sinkhorn y la división/aplicación para la mezcla
Modelado: Alto nivel antorcha.autograd.Function envoltorios que combinan los núcleos subyacentes en capas entrenables (engram gate, mHC pipeline)
DeepSeek EPv2: EP más rápido con soporte de Engram, PP y CP
Enlace EPv2: https://github.com/deepseek-ai/DeepEP/pull/605
Hoy mismo, DeepSeek también ha publicado la última versión de EPv2, entregando más rápido paralelismo experto (PE) y apoyo a Engrama / paralelismo de canalización (PP) / paralelismo de contexto (CP).
A medida que el hardware, las redes y las arquitecturas de los modelos han ido evolucionando junto con los rápidos lanzamientos de la industria como Qwen 3.6, El anterior DeepEP V1 de DeepSeek ya había acumulado demasiado bagaje histórico y demasiados problemas de rendimiento.
Esta actualización reestructura por completo Paralelismo experto. En comparación con V1, sólo necesita una fracción de los recursos de SM para alcanzar un rendimiento extremo, al tiempo que admite una mayor escala. ampliación (dentro de una misma máquina) y ampliación (en todas las máquinas).
Además, DeepSeek introdujo un sistema experimental 0 SM en esta actualización, incluyendo 0 SM Engram, 0 Paralelismo de canalización SM (PP), y 0 Paralelismo contextual SM (CP) Todos los operadores de recogida. Al mismo tiempo, se ha cambiado el backend de NVSHMEM al encendedor NCCL Gin backend.
Nuevas funciones de DeepSeek DeepEP V2
Estas son algunas de las novedades de DeepEP V2:
Totalmente JIT
NCCL Gin backend:
Sólo cabecera, extremadamente ligera
Posibilidad de reutilizar los comunicadores NCCL existentes
EPv2:
Unifica las API de alto rendimiento y baja latencia en una única interfaz y adopta un nuevo diseño GEMM.
Admite dominios de escalado mayores, hasta EP2048
Introduce el cálculo analítico del recuento de SM y QP, por lo que ya no es necesario el autoajuste.
Sigue apoyando tanto Híbrido y Directo modo
En las tareas de formación más antiguas similares a V3, el uso de SM desciende de 24 a 4-6, manteniendo el mismo rendimiento o incluso mejor
0 SM Engram (con RDMA)
0 SM PP (con RDMA)
0 SM CP (con Copy Engine)
Rendimiento de DeepSeek DeepEP V2
Tras la configuración de DeepSeek-V3, Las pruebas se realizaron con la nueva versión y con los parámetros de 8.000 fichas por lote, 7168 dimensión oculta, Los 8 mejores expertos, Envío FP8, y Combinación BF16. Los resultados son los siguientes:
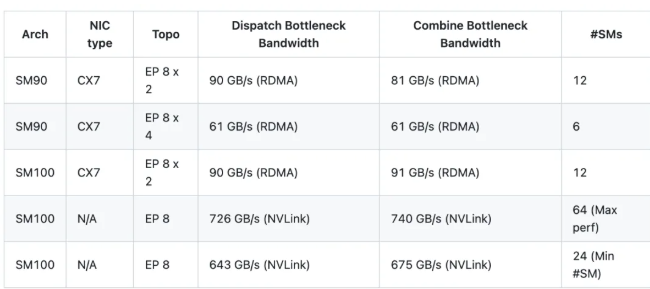
Nota: Los resultados mostrados son anchos de banda lógicos. Por ejemplo, en el caso de EP 8 x 2, El 90 GB/s El ancho de banda incluye en realidad el tráfico entre GPU locales (rangos locales).
En comparación con V1, V2 logra hasta 1,3 veces el rendimiento máximo, ahorrando tanto como 4× uso de recursos SM -una optimización crucial para seguir siendo competitivo en un panorama dominado por pesos pesados como Claude Opus 4.7.
Por último, un consejo para DeepSeek: date prisa en publicar V4 ya. Todo el mundo se está impacientando.

