
DeepSeek V4, which made the whole world wait bitterly until April, has finally arrived!
Just now, DeepSeek V4 really came!
Today, DeepSeek, the one that once broke the dominance of closed-source models almost by itself and proved that DeepSeek inizia ad aggiornarsi frequentemente to shift industry dynamics, has officially announced to global developers with the preview version of the DeepSeek-V4 series—
The civilian era of million-level context (1M Context), and a new peak in open-source Agent capabilities, world knowledge, and reasoning performance, has arrived.
DeepSeek V4 has once again achieved leadership in China and in the open-source field, mirroring the rapid rise we’ve seen as Qwen 3.6 pushed boundaries.
The technical report of V4 has also been released at the same time.

Paper address: https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf
DeepSeek V4 Models Overview: V4-Pro vs V4-Flash
DeepSeek V4-Pro: Flagship Model Specifications
The DeepSeek-V4 series includes two versions: the performance monster DeepSeek-V4-Pro, with 1.6T total parameters and 49B activated parameters.
DeepSeek V4-Flash: Efficient and Cost-Optimized Version
DeepSeek-V4-Flash is designed specially for high efficiency and economy, with 284B total parameters and 13B activated parameters.
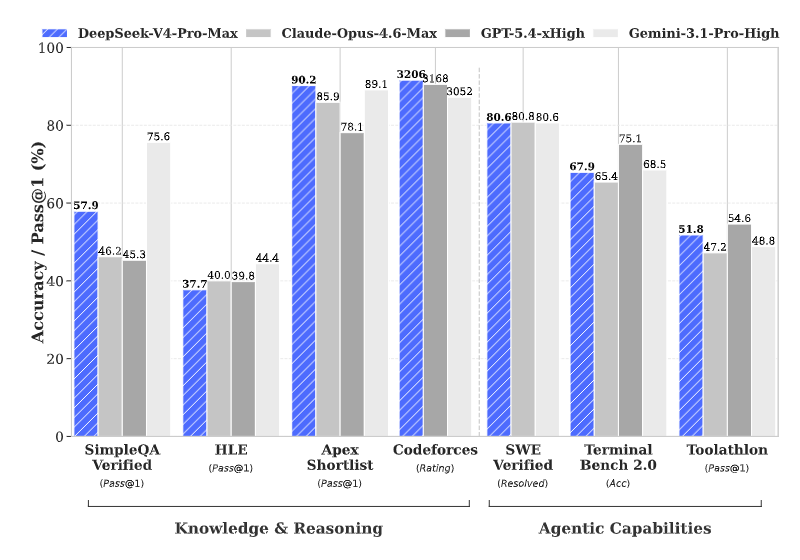
It can be said that DeepSeek-V4-Pro has reached a new peak for open-source models, benchmarking against the world’s top closed-source level.
DeepSeek V4-Pro Performance: Agent, Knowledge, and Reasoning
DeepSeek V4 Agent Capability Breakthrough
First, V4-Pro has achieved a leap-forward breakthrough in Agent capabilities, and its Agentic Coding level firmly ranks first in the open-source world.
Actual test feedback shows that its coding experience has already surpassed Sonnet 4.5, and its delivery quality is catching up with Opus 4.6 (non-thinking mode). It has now become the preferred model for internal Agent programming in the company.
DeepSeek V4 World Knowledge Benchmark Performance
Second, it has deep world knowledge reserves.
In the knowledge evaluation dimension, V4-Pro is significantly ahead of similar open-source products, and the gap with the closed-source benchmark Gemini-Pro-3.1 has been reduced to a very small range.
DeepSeek V4 Reasoning and STEM Capabilities
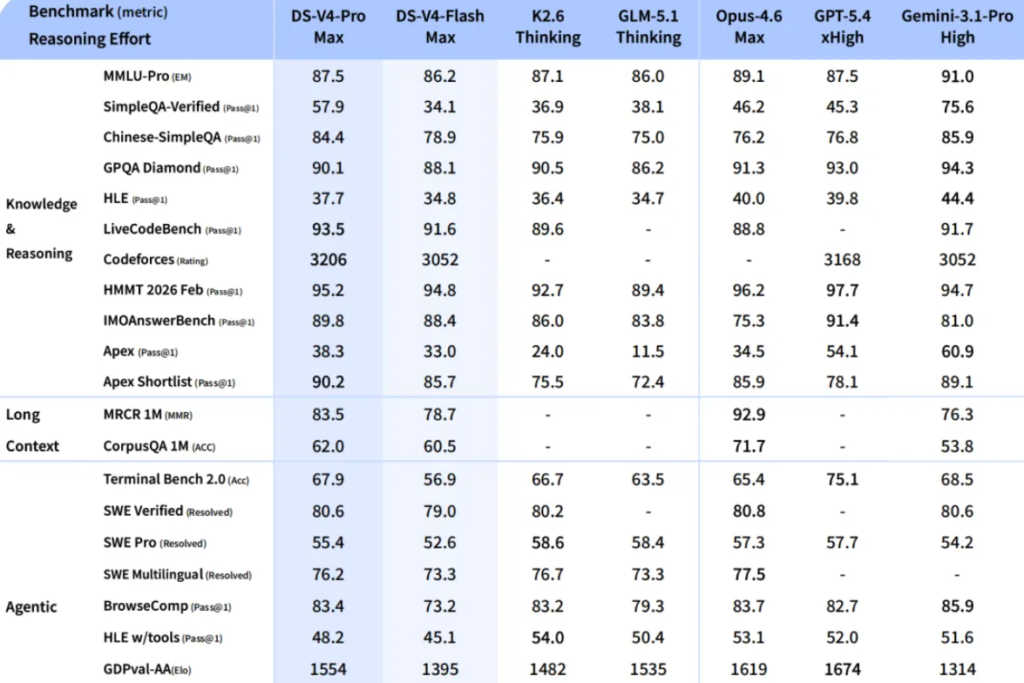
Also, it has top-tier logical reasoning performance.
In hard-core areas such as mathematics, STEM, and high-difficulty competitive programming, V4-Pro not only tops the open-source community, but also already has real combat competitiveness to challenge the strongest closed-source models in the world.
DeepSeek V4 Architecture Innovations: CSA, HCA, and mHC
Supporting these two models in looking down on the field are the “three great skills” of the underlying technology:
Hybrid Attention in DeepSeek V4 (CSA + HCA)
DeepSeek-V4 did not blindly increase hardware investment, but creatively designed a hybrid attention architecture.
Compressed Sparse Attention (CSA) compresses the KV cache along the token dimension and combines it with DSA sparse attention; Heavy Compressed Attention (HCA) carries out even more extreme compression to maintain dense computation.
This “long and short combination” strategy greatly reduces computation and memory requirements when the model handles million-word context.
Manifold-Constrained Hyper-Connection (mHC) in DeepSeek V4
To improve the stability of signal propagation and strengthen model expressiveness, V4 introduces the mHC structure, upgrading the traditional residual connection.
Muon Optimizer in DeepSeek V4 Training
The new Muon optimizer is introduced, making the training process not only converge faster, but also more stable.
It is exactly these structural innovations that allow DeepSeek-V4 to achieve a qualitative leap in inference efficiency.
In the extreme scenario of 1 million token context, DeepSeek-V4-Pro’s single-token inference computation is only 27% of the previous generation, and KV cache usage is reduced to an astonishing 10%.
DeepSeek V4-Flash Performance: Speed, Cost, and Use Cases
Compared with the Pro version, the Flash version is a faster and more efficient economical choice.
DeepSeek V4-Flash Reasoning vs Pro Comparison
Although it is slightly weaker than the Pro version in the depth of world knowledge, DeepSeek-V4-Flash keeps a logical reasoning level close to it.
DeepSeek V4 API Cost and Efficiency Advantages
Benefiting from a more streamlined parameter scale and activation mechanism, it can provide users with API access that responds faster and costs less.
DeepSeek V4 Agent Task Performance Differences
When handling basic Agent tasks, V4-Flash performs almost the same as the Pro version, but when facing extremely complex tasks, there is still room for further progress.
DeepSeek V4 Long Context Breakthrough: 1M Tokens Becomes Standard
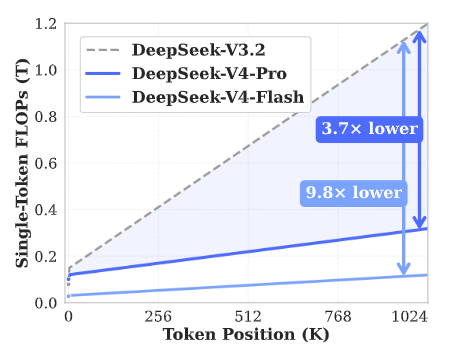
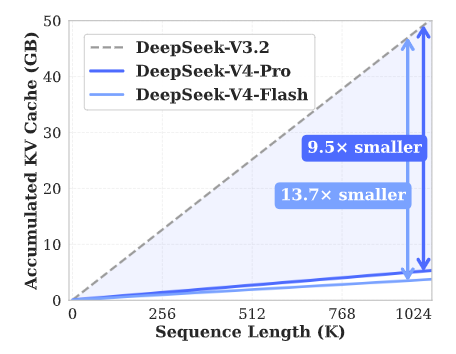
DeepSeek-V4 introduces a revolutionary attention mechanism.
Through efficient compression in the Token dimension and combining DSA sparse attention (DeepSeek Sparse Attention) technology, it achieves world-leading long-text processing capability.
DeepSeek V4 1M Context as Default Configuration
Starting today, 1M (1 million tokens) ultra-long context will become the standard configuration of DeepSeek official services.
DeepSeek V4 vs Previous Models in Memory and Compute
This innovation greatly cuts dependence on computing resources and memory.
Changes in computation and memory capacity of DeepSeek-V4 and DeepSeek-V3.2 with context length
DeepSeek V4 Agent Optimization and Ecosystem Integration
DeepSeek V4 Integration with Agent Frameworks
DeepSeek-V4 has carried out deep adaptation for mainstream Agent ecosystems such as Claude Code, OpenClaw, OpenCode, and CodeBuddy.
DeepSeek V4 Use Cases: Code and Document Generation
In scenarios such as code writing and automated document generation, its output efficiency has been significantly improved.
Example of PPT pages automatically generated by V4-Pro under a specific Agent framework
DeepSeek V4 API Update and Model Migration Guide
How to Use DeepSeek V4 API (model_name Setup)
For developers, the good news is: the API has already gone online at the same time!
You only need to simply modify model_name to access these two new flagships:
- Performance: deepseek-v4-pro
- Efficiency: deepseek-v4-flash
DeepSeek V4 Model Deprecation Timeline
Special reminder: the original deepseek-chat and deepseek-reasoner model names will serve as transitional aliases of V4, but these two old names will be officially discontinued on July 24, 2026.
DeepSeek V4 Technical Paper Insights
DeepSeek V4 CSA Compression Mechanism Explained
In V4-Pro, the compression ratio of CSA is 4. The KV cache of every 4 tokens is merged into one entry.
DeepSeek V4 HCA Global Compression Strategy
HCA takes another path. The compression ratio is pulled to 128, much more aggressive than CSA.
DeepSeek V4 Hybrid Attention Collaboration Design
The two mechanisms are alternately stacked. CSA does fine-grained retrieval, HCA does global perception.
DeepSeek V4 Training Innovations: Muon, MoE, and Distillation
DeepSeek V4 mHC Stability Optimization
mHC constrains the residual mapping matrix to avoid divergence in deep networks.
DeepSeek V4 Muon Optimizer and Training Tricks
The core of Muon is orthogonalization of gradient momentum.
DeepSeek V4 MegaMoE and System Acceleration
V4 open-sources MegaMoE, merging communication and computation into a single pipeline kernel.
DeepSeek V4 OPD Distillation and GRM Reward Model
V4 uses On-Policy Distillation and introduces Generative Reward Model for joint optimization.
Why DeepSeek V4 Matters for Open-Source AI
From the sudden rise of V3 to the efficiency revolution of V4, DeepSeek has always insisted on sharing the most top-level technologies with the community through open source.
The launch of DeepSeek-V4 is not only a jump in technical parameters, but also a strong response to the evolving AI ecosystem, standing strong amidst industry rumblings like the Anthropic Mythos leak.
- Million-level long context
- High-performance Agent systems
It proves that through architecture innovation, we can greatly lower the threshold of large models without sacrificing performance.
Now, you can immediately start the new 1M context experience in the official App or at chat.deepseek.com.
This is not just a chat box. This is a “second brain” that can hold an entire encyclopedia and understand the logic of tens of thousands of lines of code.
Reference
https://huggingface.co/collections/deepseek-ai/deepseek-v4
https://modelscope.cn/collections/deepseek-ai/DeepSeek-V4
https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf

