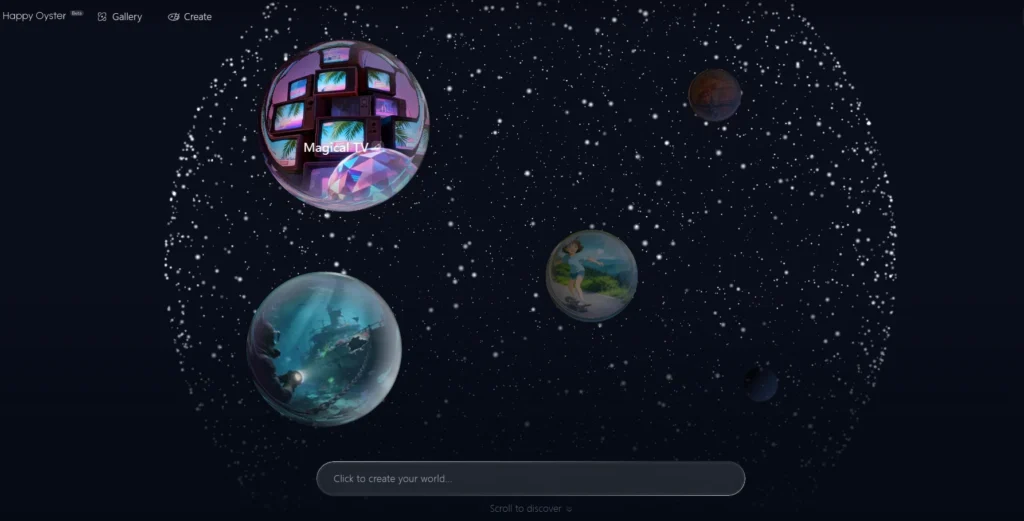
Recently, a mysterious “happy horse” suddenly rushed to the top of the Artificial Analysis leaderboard.
The AI circle was immediately filled with speculation, until Alibaba stepped forward to claim it.
Unexpectedly, just a few days later, Alibaba’s “Happy” family added another new member — HappyOyster.
Both come from the same place, the Alibaba Token Hub (ATH) innovation group established this March.
However, unlike the “happy horse” one-shot process of “write prompt, wait for rendering, receive final clip,” HappyOyster is an open-world model product that can be built and interacted with in real time.
It is based on a native multimodal architecture, behind it is a streaming generative world model that supports multimodal input and joint audio-video generation. During the generation process, it can continuously receive user instructions, with visuals responding in real time and evolving continuously.
HappyOyster focuses on two core features: Wander and Direct.
The Wander function is the first general world model that supports any style and unlimited interaction. Just input text or images, and it can generate a boundless explorable world scene, supporting over one minute of real-time movement and camera control.
The Direct function, on the other hand, is a real-time AI video directing engine based on the world model. It can continuously generate up to 3 minutes of 720p real-time video. We can control the camera, schedule characters, and change the storyline in real time through text instructions.
As for the name, there’s some thought behind it. It borrows Shakespeare’s famous line: “The world is your oyster.”
At present, HappyOyster is already online, and we got an invite code right away. Next, let’s try it hands-on.
Experience link: https://www.happyoyster.cn/
Access now requires an invite code.
HappyOyster Hands-on Test: This Alibaba World Model Is Quite Interesting
Let’s first try the flagship Wander feature.
This function supports generating worlds from text or images.
We can either directly input prompts, or separately define “Character” and “Scene” for more refined control, and also switch between first-person and third-person perspectives.
For example, we use “custom mode” and input separately:
Character: “A stylish blonde female model”
Scene: “On the streets of Paris in the 1980s.”

HappyOyster does not directly output a fixed video. Instead, within just over ten seconds, it builds a complete Paris street at night after rain. Water on the ground reflects dim yellow streetlights, cars rush by on the road, shops line both sides, and the details all follow physical rules.
Next, we can use the WASD keys to control the character’s movement, or use the arrow keys to move the camera. The character moves freely in this space, and eventually a video is formed.
The whole scene responds in real time, smooth throughout with no lag.
The system also automatically adds background music that fits the scene atmosphere, with natural synchronization between sound and visuals.
We also uploaded an anime-style first-person cycling image. Based on this static image, HappyOyster generated a complete scene with spatial structure and motion logic.
When the perspective moves forward, the extension of the road, the distribution of flower fields, and the layering of distant scenery remain coherent, without obvious stitching or jumps.
The Ghibli-style visual language and the atmosphere of falling cherry blossoms are also consistent throughout the motion.
The Wander function adapts to various styles. We even walked directly into a Van Gogh painting.
Now let’s try the Direct function. Its biggest highlight is that content can be changed at any point in the video in real time.
We gave it a Ghibli-style image, and HappyOyster immediately created a Miyazaki-like animated world: a little girl holding a red umbrella, walking on a bumpy country road after rain.
At this moment, we input the prompt: “A cute Ghibli-style kitten suddenly runs to the girl.” The model does not re-render, but directly generates a kitten running in the current scene, walking alongside the girl.
We then add another instruction: “The girl crouches down to pet the kitten.” The scene responds instantly again, the girl bends down and reaches out, the motion natural and smooth.
In short, the model can precisely adjust scenes and character actions according to the prompts we input. The visuals are smooth and natural, and every change connects seamlessly with the storyline.
HappyOyster Technical Interpretation: World Models vs Text-to-Video
After seeing the test, there’s an intuitive feeling: this thing seems different from models like Sora or Kling. It is indeed different, and the difference starts from the underlying logic.
Whether it’s Sora or Kling, text-to-video models are essentially one-shot systems. Given text or image conditions, the model organizes content, motion, and rhythm within a pre-defined time window, then delivers the result. The user gives one input and gets one output, and the process ends there. It is closed and one-time, with no room for intervention in between.
This mode is enough for generating a polished short video, but if you want to intervene midway and change anything that has already happened, it simply cannot do it.
The idea of a world model is completely different. It learns how the world will evolve next, what the current state is, what will happen after an action is applied, and what happens next. It has no preset endpoint. When there is no new input, the model continues to evolve the world based on the current state; if we inject new instructions midway, it recomputes the future based on the current state. It can be interrupted, interfered with, and rewritten at any time, a shift in dynamic interaction much like the evolution from vibe coding to wish coding.
Because of this, training a world model is much more difficult than text-to-video.
The most direct challenge is speed. A world model needs to respond instantly when a user gives instructions. Any noticeable delay will break immersion. HappyOyster adopts a streaming generation framework, compressing high-dimensional video and multimodal information into a compact dynamic latent state, greatly reducing the computational cost per step, allowing generation to proceed continuously with low latency. Text, images, and control signals like navigation are designed as condition variables that can be injected online, so the model can respond instantly at any point without resetting the generation process.
A more tricky problem is how to keep the world consistent over long periods of evolution. The longer the generation time, the more likely the scene drifts and structures degrade. Physical rules and spatial structures gradually lose constraints, and the world slowly stops looking like itself. To counter this “amnesia,” HappyOyster introduces a persistent state reuse mechanism. Through continuous transfer of historical attention states, the model efficiently inherits generated information and updates it progressively, maintaining stable scene structure and dynamic coherence over longer time spans.
In terms of audio-visual coordination, unlike treating audio as a post-processing addition, HappyOyster uses a unified audio-video generation framework. Visual and auditory signals are generated simultaneously under the same world state. Audio participates as part of world dynamics, naturally establishing cross-modal temporal alignment.
Currently, there are several representative directions in the world model field. Google’s Genie focuses on real-time interactive world modeling, but still has limitations in unified multimodal representation and joint audio-video generation. Fei-Fei Li’s World Labs follows a 3D spatial reconstruction route, emphasizing geometric consistency rather than long-sequence dynamic generation in pixel space.
HappyOyster chooses to simulate a long-sequence, real-time interactive dynamic world in pixel space, and on top of that adds joint audio-video generation capability. This is a path that few have managed to walk through before, with not many existing answers to refer to.
HappyOyster Conclusion: From Content Generation to World Building
AIGC has come to today, and content generation tools are already quite mature. Writing articles, generating images, making videos — these needs all have good solutions. But this track is quietly approaching a new turning point, from “generating content” to “building worlds.”
The emergence of HappyOyster lets us see the outline of this direction. It gives everyone a “custom digital world” that can be entered anytime, modified anytime, and responds in real time. We can wander inside it, direct inside it, and share it with others, letting them continue the story within the world we built.
In terms of application scenarios, its boundaries go far beyond entertainment within the screen. Cultural tourism exhibitions, interactive short dramas, film concept validation, brand marketing, live collaborative creation… any scenario that requires real-time perception, generation, and feedback loops naturally fits it.
Looking further ahead, once combined with cameras, sensors, spatial devices, and other hardware, what HappyOyster carries is a generative environmental system continuously driven by real-world signals.
But honestly speaking, world models are still at an early stage overall. Long-term physical consistency, causal reasoning in complex scenes, and deep understanding of real-world rules are all unresolved hard problems. HappyOyster is one of the explorations closest to a “usable product” form in this direction, but exploration means the boundaries are not yet defined.
This is both a limitation, and also the reason imagination still exists.

