Refuses to Reveal Its Name, Yet Tops Two Global Benchmarks
These past few days, the world model space has been unusually lively.
Fei-Fei Li’s spatial intelligence unicorn World Labs rolled out “Spark 2.0” in a high-profile way, and Alibaba quickly followed with its world model “Happy Oyster.”
Almost at the same time, Physical Intelligence also released a new model π 0.7, emphasizing its initial compositional generalization ability on unseen tasks and its cross-robot platform transfer characteristics.
This series of moves itself sends a signal: the focus of competition in the industry has shifted from who can do isolated actions, to who is closer to unifying “predicting the world” and “driving actions” within a single model.
At this point, a mysterious world model called MotuBrain quietly climbed to the top of two international benchmarks, without any company name attached.
If it were just first place on one leaderboard, it might not be so unusual.
But the thing is, what it took down at the same time are two leaderboards that almost represent the “two extremes” of the industry: one is WorldArena, which measures whether a world model truly understands and predicts the real world; the other is RoboTwin2.0, which evaluates robot task execution and generalization ability. One leans toward world prediction, the other toward task execution—together, they match exactly the unified problem the industry is trying to crack right now.
MotuBrain Leads Both WorldArena and RoboTwin2.0
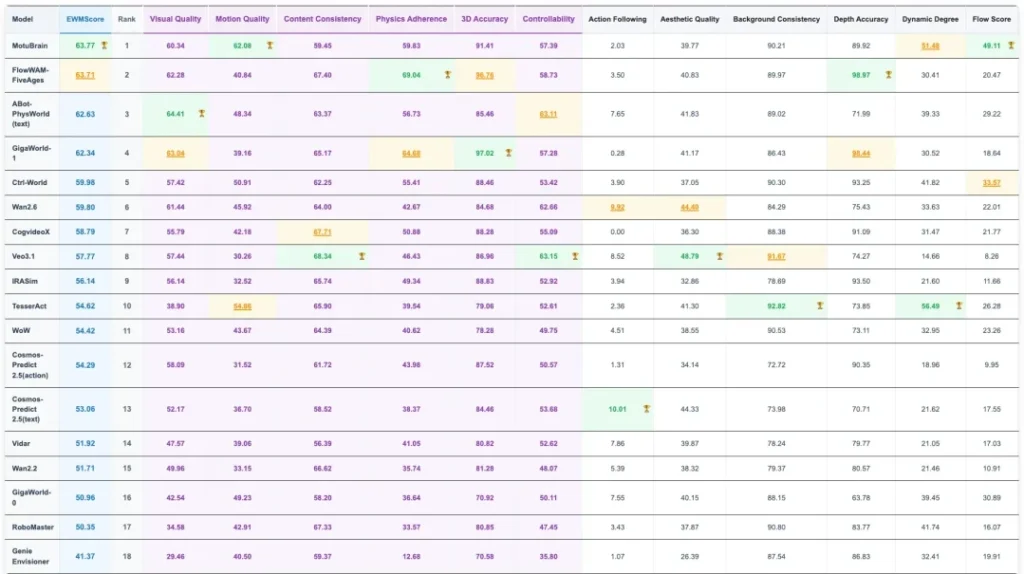
On WorldArena, MotuBrain ranked first with an overall EWM Score of 63.77. From the results, its performance surpasses models like Gaode’s ABot and Jijia’s GigaWorld-1, and it leads across key motion dimensions such as Motion Quality, Flow Score, and Motion Smoothness.
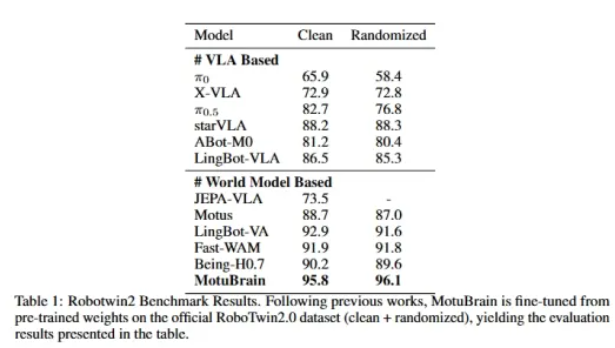
On RoboTwin2.0, MotuBrain reached 95.8 and 96.1 in Clean and Randomized settings respectively, also ranking first. It is the only model on the leaderboard with an average score above 95 in randomized environments, and in most specific tasks it achieved 100 or close to 100. Compared to models like Gaode ABot, Ant Lingbo LingBot, JEPA-VLA, and pi0.5, MotuBrain shows a dominant performance in the RoboTwin benchmark.
It is precisely this “double first place” that makes people start paying attention to this unknown model.
A quick search shows that there is still almost no information about MotuBrain online, but there is an X account registered just this month.
This brings to mind the earlier “Huanle Ma” that was later claimed by Alibaba (which also opened an X account afterward).
This mysterious world model—could it also come from some major domestic tech company?
Why MotuBrain’s Results Matter
WorldArena and RoboTwin are not the same type of test; they measure two different capabilities.
WorldArena evaluates the world model dimension: whether the model can understand motion laws, whether it can accurately infer and predict physical changes in time series, and whether it has awareness of environmental state changes. This is the ability to predict the world.
RoboTwin, on the other hand, leans toward the action model or policy model dimension—for example, whether the model can execute actions stably across multiple tasks and environments, whether it can generalize to unseen scenarios, and whether it can continuously complete complex operations. This is the ability to act in the world.
Think of it this way. The reason a human driver can drive safely in complex traffic is not just muscle memory, but constant prediction of what will happen in the next second—will the car ahead brake suddenly? Will a pedestrian cross unexpectedly? This synchronization of prediction and action is the underlying logic of human intelligence.
Most existing robotic systems lack exactly this layer. They either are good at understanding the world but don’t know how to act, or they can execute fixed actions but have no prediction of environmental changes. This split leads to robots easily failing once they leave their training scenarios.
Over the past few years, both directions have been explored, but mostly in isolation. Teams working on video generation and world models focus on whether models can realistically simulate the physical world; teams working on robot policy and VLA focus on how to make models execute reliably on specific tasks. There have been few attempts to truly unify the two, and even fewer stable results.
MotuBrain being able to take first place in both types of benchmarks at least verifies one thing at the benchmark level: unifying world prediction and action driving within a single model is a viable path.
Double First Place: Where Does It Win?
On the WorldArena leaderboard, what stands out about MotuBrain is its lead in several dimensions.
Motion Quality ranks first, meaning the actions generated by the model are more realistic, not just visually moving effects.
Flow Score ranks first, indicating a deeper understanding of continuous motion and trajectories, and the ability to stably predict large-scale motion changes—smoothly connecting one moment to the next rather than stitching frame by frame.
Motion Smoothness ranks first, meaning the generated actions better follow real physical laws, without unnatural sudden acceleration, jitter, or direction jumps.
These three dimensions are all directly related to motion. For a future world model meant to serve robots, this is exactly the most critical capability.
On the more task-execution-focused RoboTwin, this advantage is further amplified. Facing 50 tasks and two different environment settings, MotuBrain’s average score reaches 96.0, significantly higher than the second place at 92.3. The gap is almost equal to the difference between second and fifth place.
More importantly, there is stability. Half of the tasks have a 100% success rate, and 90% of tasks exceed 90%. This doesn’t just mean it can get things right—it means it can consistently reproduce results across multiple tasks and under random disturbances.
Taken together, these results point to something closer to a general robot brain: maintaining continuity and consistency at the action level while also having cross-task generalization ability.
Who Is Behind It, and What Path Are They Taking?
At present, there is very little public information about MotuBrain. But judging from the structure of its results across the two leaderboards, it is unlikely to be a traditional video model, nor a purely VLA or policy model. It represents a different kind of reasoning, distinct from the adaptive thinking found in top-tier language models, focusing intensely on pure physical intelligence.
Over the past year, exploration around world models and action models has formed several representative paths in the industry.
Some emphasize a unified world model, combining vision, language, video, and action through joint modeling—integrating video models, VLA, world models, and more—to achieve perception, planning, prediction, execution, and cross-task generalization in real environments. A typical example is Motus, released last December.
Some lean more toward a “imagine first, then act” path. For example, Lingbot-VA, released at the end of January this year, first uses a video model to predict future video, and then guides robot action decisions in reverse, merging both into one model.
Others follow a “simultaneously infer future states + generate actions” approach—the so-called World Action Model—where prediction and action happen together, such as NVIDIA’s DreamZero released in early February.
From MotuBrain’s performance this time, it may be following a path closer to the World Action Model, combining the ability of a world model to infer environments and future states, with the execution ability of an action model in real tasks.
This would also explain why it can top both “world modeling” and “action execution” benchmarks.
Conclusion
If you break down a robot, you can think of its “hands and feet” as hardware, and its “brain” as software.
Over the past few years, the iteration speed of robot hardware has been obvious—motion control is becoming more precise, sensors more abundant, costs lower. But what truly limits large-scale deployment of robots is that brain that directs tasks.
Today’s robots are essentially still “specialized systems trained for specific tasks.” Change the scenario, change the object, change the instruction, and they may completely fail. To a large extent, this comes down to intelligence.
The goal of embodied intelligence is to build a unified model—one that can understand the physical world, predict state changes, and based on that generate reliable actions, adapting to any task and scenario. This leap is as transformative for robotics as moving from vibe coding to wish coding has been for the AI programming sphere.
Capital has already given its judgment with real money.
Looking at several recent large funding rounds, it’s not hard to see that money is flowing intensively toward companies building robot “brains.” On the surface, they are investing in robots, but in reality, they may be competing for the entry point of the next-generation “robot operating system” or “general physical brain.”
Seen this way, the world+action unified architecture represented by MotuBrain happens to sit right at the core of this strategic race.
As for which team is behind MotuBrain, and what it will bring next, that question probably won’t remain unanswered for long.

