
A few days ago, OpenAI officially released its brand-new large model, GPT-5.4-Cyber. Like many people online have said, this model gives a very strong sense of déjà vu.
This new model, in its target users, application scenarios, and even marketing strategy, almost completely mirrors Anthropic’s recently released Claude Mythos. This kind of “close combat” has reached a point where it’s no longer even disguised. Even The New York Times pointed it out bluntly in a recent headline: “Like Anthropic, OpenAI…”
This trend of homogenization is not just at the level of base models. If you look at the series of products released by these two companies recently, you’ll notice they are becoming mirrors of each other.
Under the spotlight of the capital market, this convergence becomes even more obvious. Their valuations in the secondary market are now extremely close. Anthropic has even slightly surpassed OpenAI recently, driven by its rapid expansion in the enterprise market. Capital is always sensitive—through its lens, these two unicorns are growing the same horns.
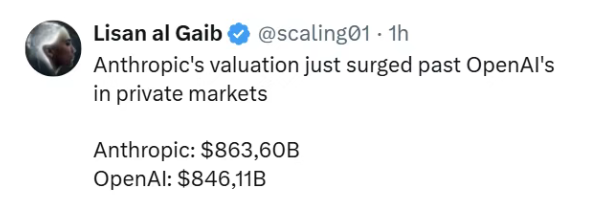
It seems that the homogenization of base models will inevitably lead to convergence in upper-layer applications.
Today, what I want to talk about are two benchmark tools representing the current peak of AI-assisted programming: OpenAI’s Codex and Anthropic’s Claude Code. From once going in completely different directions to now arriving at the same destination, how did they gradually grow into the same shape?
From Divergence to Convergence: The Evolution of Two Giants
If we go back a few years, Codex and Claude Code were products of entirely different technical philosophies.
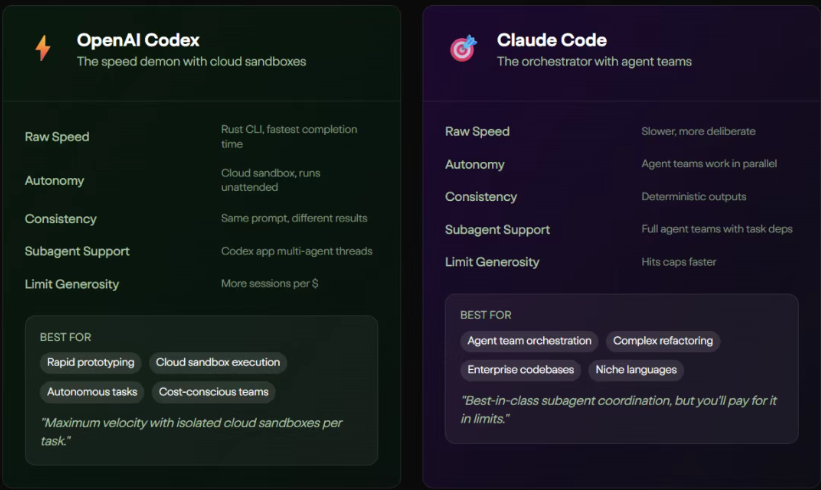
Codex’s underlying logic was essentially “speed above all.” It felt like a senior developer with five years of experience following behind you, always ready to autocomplete code.
In OpenAI’s vision, Codex was a lightweight, highly interactive terminal agent. It emphasized rapid iteration and interactive programming. Its execution speed was extremely fast—powered by Cerebras WSE-3 hardware, it could reach a throughput of 1000 tokens per second. In actual workflows, Codex offered three clear approval modes: suggestion, auto-edit, and full automation, keeping developers constantly in the loop. This design fit perfectly with developers who needed rapid prototyping and high-frequency interaction.
On the other hand, Claude Code had a “cold” and restrained architect-like personality from the very beginning.
Anthropic gave it the DNA to handle extremely complex tasks. It relied on a massive context window of up to 1 million tokens, along with a unique “compression” technique to enable effectively unlimited conversations. Claude Code’s philosophy was “global control, act after planning.” Before executing any action, it would first use agent-based search to fully understand the entire codebase, then coordinate consistent modifications across multiple files. For enterprise-level refactoring tasks involving tens of thousands of lines of code, Claude Code showed astonishing dominance.
However, as time passed and use cases expanded downward, these two originally very different tools began copying each other.
When handling complex projects, the biggest bottleneck for a single AI model is context pollution. If you ask an AI to refactor an authentication module, after reading 40 files, it often forgets the design pattern of the first file. To solve this pain point, both companies arrived at almost identical solutions: assign independent context windows to each subtask.
OpenAI quickly launched a new macOS desktop app, isolating tasks into different threads by project and running them independently in cloud sandboxes. Anthropic introduced an agent team architecture, allowing developers to spawn multiple sub-agents that share task lists and dependencies while working in parallel within separate contexts. Whether it’s called “cloud sandbox” or “agent team,” the core engineering idea is now completely aligned.
Even on benchmark scoreboards, they show a delicate balance. GPT-5.3-Codex leads in Terminal-Bench 2.0 with a score of 77.3%, while Claude Code achieves 80.8% on the more complex SWE-bench Verified. Each dominates its own strong domain while aggressively trying to cover its weaknesses.
The OpenClaw Effect: The Invisible Force Breaking Down Walls
If internal strategy is the cause of convergence, then the pressure from the open-source ecosystem is an external force that cannot be ignored. Here, we have to mention OpenClaw.
As a workflow framework from the open-source community, OpenClaw effectively tore down the ecosystem walls built by tech giants. It standardized the interaction between large models and local terminal toolchains.
In the past, things like how to elegantly let a model call local Git commits, how to safely run test scripts in a sandbox, and how to perform multi-step reasoning verification were all proprietary “black technologies” that Codex and Claude Code were proud of.
But OpenClaw abstracted these processes into general protocols. This means developers no longer need to be locked into a specific platform just to use a certain collaboration pattern. The open-source movement made standardization an unstoppable trend. Faced with this, both OpenAI and Anthropic had no choice but to lower their guard and adapt to these open standards.
When underlying technical barriers are flattened by open-source forces like OpenClaw, and all advanced features become standard configurations, the only way forward for Codex and Claude Code is endless competition at the level of subtle user experience.
That’s why they feel more and more alike. Under a standardized framework, there is often only one optimal solution—just like convergent evolution in biology.
Codex Is Catching Up to Claude Code
Although Claude Code and Codex are converging, differences still exist. In some aspects, Codex is even becoming more favored by developers.
A few days ago, in the r/ClaudeCode community, a senior engineer with 14 years of experience (user u/Canamerican726) shared a very hardcore evaluation.
He spent 100 hours using Claude Code and 20 hours using Codex on a complex project with 80,000 lines of code.
From his perspective, using Claude Code felt like supervising an engineer racing against a deadline—it moved extremely fast but often ignored the rules written in CLAUDE.md, and tended to pile code into existing files rather than refactor.
In contrast, Codex felt like a steady, experienced developer with 5–6 years of experience. Although 3–4 times slower, it would pause to think and refactor along the way, and strictly follow instruction boundaries. This level of autonomy made the engineer comfortable enough to hand off tasks and focus on other work.
Similar opinions appeared on platforms like X. Researcher Aran Komatsuzaki noted that Claude Code still leads in frontend tasks, but Codex is more solid in backend planning and maintaining up-to-date information due to frequent web searches.

In real-world discussions, developers pointed out that models based on Opus run fast but often accumulate “code cleanliness debt,” while Codex moves slower but cleans as it goes. Some even summarized a rule of thumb: when the context window usage hits 70%, start a new session immediately, or hidden bugs are likely to appear.
These firsthand experiences show clearly that as the capabilities of these tools overlap more and more, what ultimately determines developer preference are small experiential differences—things like “bug-fixing cost” and “mental maintenance load.” For Chinese users, there are also some additional challenges.
A Cold Reflection: The Hidden Ecosystem War Behind Homogenization
Of course, which tool is better still depends on the developer—and their own skill level. As u/Canamerican726 concluded: if you don’t understand software engineering, both tools will produce poor results. Tools are not the same as skills.
This statement punctures a long-standing illusion in AI programming tools. We once believed that with a powerful enough AI assistant, even someone with no background could build enterprise-level applications alone. But reality is different.
Claude Code requires a highly focused and skilled “driver,” or it can easily lose direction in large codebases. Codex, although more independent, still needs precise system context from the developer to perform at its best.
So when tool capabilities become highly homogenized, where do these companies’ real competitive advantages move?
The answer lies in pricing strategies and financial realities. For the same task, Claude Code often consumes 3–4 times more tokens than Codex, making it more expensive. For enterprise teams, using Claude Code can cost $100–$200 per developer per month. Codex, meanwhile, bundles its capabilities into more affordable subscription plans and leverages the massive GitHub ecosystem to attract users.
Anthropic’s ambition is to deeply embed Claude Code into the workflows of well-funded tech giants. For example, Stripe enabled 1,370 engineers to use Claude Code to complete a cross-language migration in four days—a task that would have taken weeks for a team of ten. Ramp used it to reduce incident response time by 80%. OpenAI, on the other hand, relies on its pervasive ecosystem reach to make Codex the default choice for many everyday developers.
This is no longer just a technical competition—it’s a war of ecosystem lock-in, pricing strategy, and user habit formation.
The Developer’s Crossroads
Looking back at the past year, the release of GPT-5.4-Cyber is just a small footnote in a much longer battle. The convergence of Codex and Claude Code signals that AI programming tools have moved from an early experimental phase full of novelty into a mature, industrialized stage.
Today, Claude Code generates 135,000 GitHub commits per day, already accounting for about 4% of all public commits. In the near future, most boilerplate code, basic test cases, and routine refactoring will likely be handled quietly in the background by these increasingly similar AI agents.
Faced with two super tools that are nearly identical in capability and increasingly similar in experience, what remains of the human developer’s core value?
Perhaps the era of tool advantage is coming to an end. When everyone holds the same sharp weapon, what determines success will no longer be who has faster code completion—but who can define problems better, who has broader system architecture vision, and who can find uniquely human irreplaceability in a world filled with AI-generated code.

