A Chinese team open-sourced LingBot-Map, and with only an ordinary camera, it achieved 10,000-frame streaming 3D reconstruction, drawing 1.2 million viewers across the internet.
A camera that costs just dozens of yuan beats LiDAR systems worth tens of thousands.
Unexpectedly, the open-sourced LingBot-Map from the Chinese team directly ignited the global robotics community.
This is a streaming 3D reconstruction foundation model. With only a single RGB camera—no LiDAR, no depth sensor—it builds a complete 3D map in real time at 20 FPS.

The most striking part: even after running continuously for 10,000 frames, the accuracy barely drops.
An AI researcher at Agility Robotics said, “I’ve been waiting for this day for too long.”

Even Andrew Davison personally stepped in to praise it:
It looks like impressive SLAM thinking has gone into this. Congratulations on the results.
Davison almost never comments publicly on specific engineering projects. When he actively reposts something and uses the word “impressive,” people in the field will take a closer look.

LingBot-Map Sparks the SLAM World — Industry Leaders Say “Finally”
LingBot-Map makes robots truly “understand” the whole world. Its open-source release drew 1.2 million viewers.
Multiple top KOLs reposted and liked it, gaining heavyweight recognition across the industry.
So what does LingBot-Map—praised by a SLAM pioneer and long-awaited by researchers—actually look like in practice?
The real-world tests released by the team give the answer.
In an aerial scene, the camera scans over an entire urban block from above. LingBot-Map reconstructs building facades, roof structures, streets, and roadside trees into a complete 3D point cloud in real time—even rooftop air-conditioning units can be distinguished.
In an indoor navigation scenario, the camera moves from the kitchen into the living room and through a corridor. Lighting and structure keep changing, yet the reconstructed multi-room 3D map aligns strictly in space, with no misalignment or ghosting between rooms.
A low-light corridor becomes an extreme test. The camera moves through an almost pitch-black narrow hallway. Traditional vision methods usually fail here, but LingBot-Map still outputs a coherent corridor structure and stable trajectory.
Even more interesting, the team fed cartoon-style videos generated by LingBot-World into LingBot-Map, and it still completed stable 3D reconstruction.
The input is an AI-generated virtual Japanese street. The output is a 3D point cloud with precise spatial coordinates. The compatibility between the two models directly connects the pipeline from “virtual world → 3D spatial understanding.”
Trajectory comparison makes it even clearer.
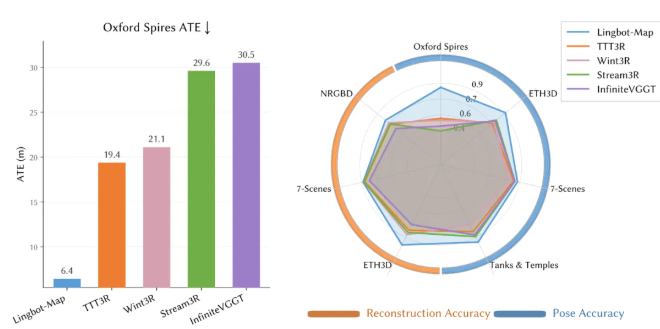
On the Oxford Spires and Tanks & Temples datasets, LingBot-Map’s predicted trajectory (orange) almost completely overlaps with the ground truth (blue), while competing methods TTT3R and WinT3R show severe drift.
Inside LingBot-Map — A “Selective Memory” System
The core difficulty of streaming 3D reconstruction is just one thing: how to let the model “build while seeing,” without forgetting the past or exhausting memory.
Traditional 3D reconstruction is “capture first, process later.”
Streaming reconstruction requires the system to continuously localize and map while receiving new frames, all while strictly controlling computation and memory costs.
Previous solutions were stuck in trade-offs.
Some compressed too aggressively and gradually forgot earlier observations. Some cached all historical frames, causing memory to grow linearly with sequence length. Others combined deep learning models with traditional SLAM backends—decent results, but requiring manual tuning and lacking real-time performance.
LingBot-Map borrows a structural insight from classical SLAM.
To build maps while moving in unknown environments, robots need to maintain spatial memory at multiple granularities. Traditional SLAM uses hand-crafted geometric constraints to manage this, limiting flexibility.
LingBot-Map internalizes this structure into the Transformer attention mechanism, letting the model learn what to remember and what to forget.
This mechanism is called Geometric Context Attention (GCA), maintaining three layers of memory.
- Anchor — remember “where I started.”
The first few frames act as anchor frames, fixing the coordinate system and scale baseline, like GPS base stations. Even at frame 10,000, the model still knows where frame 1 is. - Pose-reference window — remember “what’s around me.”
It keeps the most recent dozens of frames with full visual information, capturing dense geometric details near the current position—like the view through a car windshield. - Trajectory memory — remember “where I’ve been.”
Distant frames don’t keep full visual detail. Each frame is compressed into just 6 compact tokens, storing key geometric information of the entire trajectory. Like a rearview mirror—you don’t see every street number, but you know where you came from.
Three layers of memory sound complex, but in practice they are extremely efficient.
For a 10,000-frame video, standard causal attention caches about 5 million tokens, while GCA uses only about 70,000. Each new frame adds around 500 tokens in standard methods, but only 6 tokens in GCA. Memory growth is reduced by about 80×.
That’s why LingBot-Map can process ultra-long videos with constant memory, while others crash after a few thousand frames.
LingBot-Map Training Strategy and Benchmark Results
The team used a two-stage training strategy.
In stage one, they trained a base model on 29 datasets covering indoor, outdoor, synthetic, and real-world scenes, building general geometric understanding.
In stage two, they introduced GCA and gradually increased the number of views from 24 to 320, allowing the model to first learn short sequences and then long trajectories.
In evaluation, the paper reports results across five benchmarks.
On Oxford Spires (large-scale mixed indoor-outdoor trajectories at the University of Oxford), LingBot-Map achieves an ATE error of 6.42 meters, compared to 18.16 meters for the second place—nearly 3× better.
Notably, this accuracy even surpasses offline methods that process all frames at once (12.87) and traditional iterative optimization methods (10.52).
When scaling from 320 frames to 3,840 frames, ATE only increases from 6.42 to 7.11, showing almost no degradation with sequence length.
On ETH3D (with laser-scanned ground truth), reconstruction F1 reaches 98.98, improving over the second place (77.28) by more than 21 percentage points.
On Tanks & Temples (large outdoor structures), ATE is 0.20 meters versus 0.76 meters for second place.
On 7-Scenes (indoor RGB-D), ATE is 0.08 meters—the best result.
What LingBot-Map Means for Robotics
Academia looks at ATE and F1, but robotics companies calculate a different equation.
First is hardware cost.
An industrial-grade LiDAR costs thousands to tens of thousands of dollars. Add IMUs, calibration toolchains, and software adaptation, and perception alone can take up one-third of the entire robot cost.
LingBot-Map only needs a camera that costs a few dozen yuan.
For categories like home service robots and low-speed delivery vehicles, where price sensitivity is extreme, removing LiDAR matters far more than adding another chip.
Second is long-duration autonomous navigation.
Robots operating in large logistics centers or urban environments need to run for hours continuously. Traditional systems run into memory limits over long sequences.
LingBot-Map’s ability to process 10,000+ frames with constant memory makes long-duration autonomy in large spaces feasible.
Another aspect is dexterous manipulation.
This connects to LingBot-Depth, open-sourced earlier.
When robots try to grasp transparent glass or reflective metal containers, traditional depth cameras are almost “blind.” These materials don’t reflect reliable signals, leading to large holes in depth maps.
LingBot-Depth uses Masked Depth Modeling (MDM) to solve this.
During training, parts of the depth map are intentionally masked, forcing the model to infer distances from RGB textures and contours.
As a result, it achieves state-of-the-art performance on benchmarks like NYUv2 and ETH3D, with depth accuracy even surpassing industrial-grade depth cameras.
The model has been certified by Orbbec’s depth vision lab, and both sides have formed a strategic partnership to develop next-generation depth cameras. In real-world tests, it achieved a 50% grasp success rate on transparent storage boxes.
LingBot-Depth handles “seeing how far each pixel is,” while LingBot-Map handles “understanding the full 3D scene in real time.”
Together, they close the loop of spatial perception for robots.
Robotic arms facing glass cups in kitchens, test tubes in labs, or reflective metal containers in warehouses now have reliable 3D spatial references.
LingBot-Map Completes the Embodied AI Puzzle

Looking at the bigger picture, the open-sourcing of LingBot-Map is not an isolated event, but a key milestone in a clear embodied AI roadmap.
Back in January, the team open-sourced four models during their “Embodied Intelligence Evolution Week.”
LingBot-Depth handles depth perception.
LingBot-VLA is an embodied large model, achieving record real-world success rates in the GM-100 benchmark at Shanghai Jiao Tong University.
LingBot-World targets Google Genie 3, enabling real-time interaction at 16 FPS.
LingBot-VA introduced autoregressive joint modeling of video and actions, improving real-world task success rates by 20% over Pi0.5.
But something was missing.
Depth estimation provides frame-level “points,” while 3D mapping provides continuous “surfaces.” The intermediate layer—real-time spatial understanding—was absent.
LingBot-Map fills that gap precisely.
Now, the full embodied AI stack forms a closed loop:
See the world (Depth) → Understand space (Map) → Simulate physics (World) → Decide and act (VLA/VA)
Every component in this chain is open-sourced under the Apache 2.0 license, with code, weights, and technical reports released on platforms like Hugging Face and ModelScope.
Globally, this level of openness is rare.
For the robotics industry, what a single camera can do has just expanded.
References
- LingBot-Map. Hugging Face Repository (huggingface.co/robbyant/lingbot-map)
- LingBot-Map. ModelScope Model Page (modelscope.cn/models/Robbyant/lingbot-map)
- LingBot-Map. GitHub Repository (github.com/Robbyant/lingbot-map)
- LingBot-Map: Streaming 3D Reconstruction with Geometric Context Attention. arXiv Preprint (arxiv.org/abs/2604.14141)
- LingBot-Map Official Homepage (technology.robbyant.com/lingbot-map)

