Une équipe chinoise a mis LingBot-Map en libre accès et, avec une simple caméra, a réalisé une reconstruction 3D en continu de 10 000 images, attirant 1,2 million de téléspectateurs sur l'internet.
Une caméra qui ne coûte que quelques dizaines de yuans bat des systèmes LiDAR qui valent des dizaines de milliers d'euros.
De manière inattendue, la carte LingBot-Map de l'équipe chinoise a directement enflammé la communauté mondiale de la robotique.
Il s'agit d'un modèle de fondation à reconstruction 3D en continu. Avec une seule caméra RVB - pas de LiDAR, pas de capteur de profondeur - il construit une carte 3D complète en temps réel à 20 FPS.

L'aspect le plus frappant est que, même après une exécution continue de 10 000 images, la précision ne diminue pratiquement pas.
Un chercheur en IA d'Agility Robotics a déclaré : “J'attends ce jour depuis trop longtemps”.”

Même Andrew Davison est intervenu personnellement pour en faire l'éloge :
Il semble que le SLAM ait fait l'objet d'une réflexion impressionnante. Félicitations pour les résultats.
M. Davison ne commente presque jamais publiquement des projets d'ingénierie spécifiques. Lorsqu'il réaffiche activement un projet et qu'il utilise le mot “impressionnant”, les spécialistes du domaine s'y intéressent de plus près.

LingBot-Map stimule le monde du SLAM - Les leaders de l'industrie disent “enfin”.”
LingBot-Map permet aux robots de “comprendre” véritablement le monde entier. Son lancement en code source libre a attiré 1,2 million de téléspectateurs.
De nombreux KOLs de premier plan l'ont reposté et aimé, ce qui lui a valu une reconnaissance de poids dans tout le secteur.
Alors, à quoi ressemble LingBot-Map - vanté par un pionnier du SLAM et attendu depuis longtemps par les chercheurs - dans la pratique ?
Les tests en conditions réelles publiés par l'équipe donnent la réponse.
Dans une scène aérienne, la caméra balaie un bloc urbain entier depuis le ciel. LingBot-Map reconstruit les façades des bâtiments, les structures des toits, les rues et les arbres en bordure de route dans un nuage de points 3D complet en temps réel - même les unités de climatisation sur les toits peuvent être distinguées.
Dans un scénario de navigation intérieure, la caméra se déplace de la cuisine au salon et traverse un couloir. L'éclairage et la structure ne cessent de changer, mais la carte 3D reconstituée de plusieurs pièces s'aligne rigoureusement dans l'espace, sans décalage ni image fantôme entre les pièces.
Un couloir peu éclairé devient un test extrême. La caméra se déplace dans un couloir étroit presque noir. Les méthodes de vision traditionnelles échouent généralement ici, mais LingBot-Map produit toujours une structure de couloir cohérente et une trajectoire stable.
Plus intéressant encore, l'équipe a introduit dans LingBot-Map des vidéos de type dessin animé générées par LingBot-World, et la reconstruction 3D est restée stable.
L'entrée est une rue japonaise virtuelle générée par l'IA. Le résultat est un nuage de points 3D avec des coordonnées spatiales précises. La compatibilité entre les deux modèles relie directement le pipeline “monde virtuel → compréhension spatiale en 3D”.”
La comparaison des trajectoires rend les choses encore plus claires.
Sur les ensembles de données Oxford Spires et Tanks & Temples, la trajectoire prédite par LingBot-Map (orange) se superpose presque entièrement à la vérité terrain (bleu), tandis que les méthodes concurrentes TTT3R et WinT3R présentent une dérive importante.
LingBot-Map : un système de “mémoire sélective
La principale difficulté de la reconstruction 3D en continu tient en une seule chose : comment permettre au modèle de “construire en voyant”, sans oublier le passé ni épuiser la mémoire.
La reconstruction 3D traditionnelle consiste à “capturer d'abord, traiter ensuite”.”
La reconstruction en continu exige que le système localise et cartographie en permanence tout en recevant de nouvelles images, tout en contrôlant strictement les coûts de calcul et de mémoire.
Les solutions précédentes étaient bloquées par des compromis.
Certains ont procédé à une compression trop agressive et ont progressivement oublié les observations antérieures. D'autres ont mis en cache toutes les images historiques, ce qui a entraîné une croissance linéaire de la mémoire en fonction de la longueur de la séquence. D'autres ont combiné des modèles d'apprentissage profond avec des backends SLAM traditionnels - des résultats décents, mais nécessitant un réglage manuel et manquant de performance en temps réel.
LingBot-Map emprunte un concept structurel au SLAM classique.
Pour établir des cartes tout en se déplaçant dans des environnements inconnus, les robots doivent conserver une mémoire spatiale à plusieurs granularités. La méthode SLAM traditionnelle utilise des contraintes géométriques élaborées à la main pour gérer cette mémoire, ce qui limite la flexibilité.
LingBot-Map internalise cette structure dans le mécanisme d'attention du Transformer, permettant au modèle d'apprendre ce qu'il faut retenir et ce qu'il faut oublier.
Ce mécanisme, appelé attention contextuelle géométrique (ACG), maintient trois couches de mémoire.
- Ancrage - se souvenir de “là où j'ai commencé”.”
Les premières images servent de points d'ancrage, fixant le système de coordonnées et la ligne de base de l'échelle, à l'instar des stations de base GPS. Même à l'image 10 000, le modèle sait toujours où se trouve l'image 1. - Fenêtre de référence - se souvenir de “ce qui m'entoure”.”
Il conserve les dizaines d'images les plus récentes avec des informations visuelles complètes, capturant des détails géométriques denses à proximité de la position actuelle, comme la vue à travers le pare-brise d'une voiture. - Mémoire de la trajectoire - se rappeler “où j'ai été”.”
Les images éloignées ne conservent pas tous les détails visuels. Chaque image est comprimée en seulement 6 jetons compacts, stockant les informations géométriques clés de l'ensemble de la trajectoire. Comme dans un rétroviseur, vous ne voyez pas tous les numéros de rue, mais vous savez d'où vous venez.
Trois couches de mémoire peuvent sembler complexes, mais dans la pratique, elles sont extrêmement efficaces.
Pour une vidéo de 10 000 images, l'attention causale standard met en mémoire environ 5 millions de jetons, tandis que l'ACG n'en utilise qu'environ 70 000. Chaque nouvelle image ajoute environ 500 tokens dans les méthodes standard, mais seulement 6 tokens dans GCA. La croissance de la mémoire est réduite d'environ 80×.
C'est pourquoi LingBot-Map peut traiter des vidéos très longues avec une mémoire constante, alors que d'autres se plantent après quelques milliers d'images.
Stratégie de formation de LingBot-Map et résultats de l'analyse comparative
L'équipe a utilisé une stratégie de formation en deux étapes.
Au cours de la première étape, ils ont entraîné un modèle de base sur 29 ensembles de données couvrant des scènes d'intérieur, d'extérieur, synthétiques et réelles, afin d'acquérir une compréhension générale de la géométrie.
Au cours de la deuxième étape, ils ont introduit l'ACG et augmenté progressivement le nombre de vues de 24 à 320, ce qui a permis au modèle d'apprendre d'abord des séquences courtes, puis des trajectoires longues.
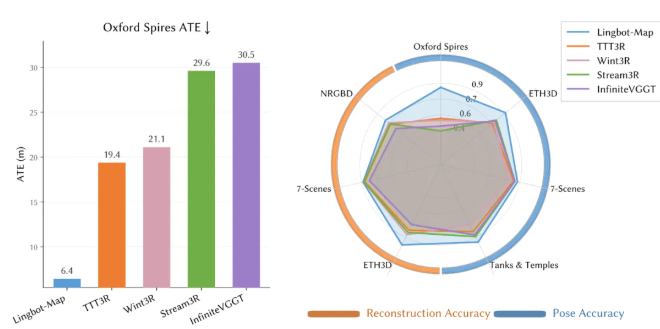
En ce qui concerne l'évaluation, le document présente les résultats obtenus pour cinq critères de référence.
Sur Oxford Spires (trajectoires mixtes intérieures-extérieures à grande échelle à l'Université d'Oxford), LingBot-Map obtient une erreur ATE de 6,42 mètres, contre 18,16 mètres pour la deuxième place, soit une amélioration de près de 3 fois.
Cette précision dépasse même les méthodes hors ligne qui traitent toutes les images à la fois (12,87) et les méthodes d'optimisation itératives traditionnelles (10,52).
Lorsque l'on passe de 320 images à 3 840 images, l'ATE n'augmente que de 6,42 à 7,11, ce qui montre qu'il n'y a pratiquement pas de dégradation en fonction de la longueur de la séquence.
Sur ETH3D (avec une vérité terrain scannée au laser), la reconstruction F1 atteint 98,98, améliorant la deuxième place (77,28) de plus de 21 points de pourcentage.
Sur les chars et temples (grandes structures extérieures), l'ATE est de 0,20 mètre contre 0,76 mètre pour la deuxième place.
Sur 7 scènes (RVB-D intérieur), l'ATE est de 0,08 mètre, soit le meilleur résultat.
Ce que LingBot-Map signifie pour la robotique
Le monde universitaire s'intéresse à l'ATE et à la F1, mais les entreprises de robotique calculent une équation différente.
Le premier est le coût du matériel.
Un LiDAR de qualité industrielle coûte des milliers, voire des dizaines de milliers de dollars. Si l'on ajoute les IMU, les chaînes d'outils d'étalonnage et l'adaptation du logiciel, la perception à elle seule peut représenter un tiers du coût total du robot.
LingBot-Map n'a besoin que d'une caméra qui coûte quelques dizaines de yuans.
Pour des catégories telles que les robots de service à domicile et les véhicules de livraison à faible vitesse, où la sensibilité au prix est extrême, l'élimination du LiDAR est bien plus importante que l'ajout d'une autre puce.
La seconde est la navigation autonome de longue durée.
Les robots opérant dans les grands centres logistiques ou les environnements urbains doivent fonctionner pendant des heures en continu. Les systèmes traditionnels se heurtent à des limites de mémoire sur de longues séquences.
La capacité de LingBot-Map à traiter plus de 10 000 images avec une mémoire constante rend possible une autonomie de longue durée dans de grands espaces.
Un autre aspect est la manipulation dextre.
Il se connecte à LingBot-Depth, qui a été mis en libre accès plus tôt.
Lorsque les robots essaient de saisir des récipients en verre transparent ou en métal réfléchissant, les caméras de profondeur traditionnelles sont presque “aveugles”. Ces matériaux ne renvoient pas de signaux fiables, ce qui entraîne des trous importants dans les cartes de profondeur.
LingBot-Depth utilise la modélisation en profondeur masquée (MDM) pour résoudre ce problème.
Lors de l'apprentissage, certaines parties de la carte de profondeur sont intentionnellement masquées, ce qui oblige le modèle à déduire les distances à partir des textures et des contours RVB.
Par conséquent, il atteint des performances de pointe sur des bancs d'essai tels que NYUv2 et ETH3D, avec une précision de profondeur dépassant même celle des caméras de profondeur de qualité industrielle.
Le modèle a été certifié par le laboratoire de vision en profondeur d'Orbbec, et les deux parties ont formé un partenariat stratégique pour développer la prochaine génération de caméras de profondeur. Lors d'essais en conditions réelles, il a obtenu un taux de réussite de 50% sur des boîtes de stockage transparentes.
LingBot-Depth permet de “voir à quelle distance se trouve chaque pixel”, tandis que LingBot-Map permet de “comprendre l'ensemble de la scène en 3D en temps réel”.”
Ensemble, ils bouclent la boucle de la perception spatiale pour les robots.
Les bras robotisés placés face à des gobelets en verre dans les cuisines, à des tubes à essai dans les laboratoires ou à des conteneurs métalliques réfléchissants dans les entrepôts disposent désormais de références spatiales 3D fiables.
LingBot-Map complète le puzzle de l'IA incarnée

Dans une perspective plus large, l'ouverture de LingBot-Map n'est pas un événement isolé, mais une étape clé d'une feuille de route claire en matière d'IA incarnée.
En janvier dernier, l'équipe a mis en libre accès quatre modèles lors de la “Semaine de l'évolution de l'intelligence incarnée”.”
LingBot-Depth gère la perception de la profondeur.
LingBot-VLA est un grand modèle incarné qui a atteint des taux de réussite record dans le monde réel lors du test de référence GM-100 à l'Université Jiao Tong de Shanghai.
LingBot-World cible Google Genie 3, permettant une interaction en temps réel à 16 FPS.
LingBot-VA a introduit une modélisation autorégressive conjointe de la vidéo et des actions, améliorant les taux de réussite des tâches dans le monde réel de 20% par rapport à Pi0.5.
Mais il manquait quelque chose.
L'estimation de la profondeur fournit des “points” au niveau de l'image, tandis que la cartographie 3D fournit des “surfaces” continues. La couche intermédiaire - la compréhension spatiale en temps réel - était absente.
LingBot-Map comble précisément cette lacune.
Désormais, l'ensemble de la pile d'IA incarnée forme une boucle fermée :
Voir le monde (profondeur) → Comprendre l'espace (carte) → Simuler la physique (monde) → Décider et agir (VLA/VA)
Chaque élément de cette chaîne est libre de droits sous la licence Apache 2.0, le code, les poids et les rapports techniques étant publiés sur des plateformes telles que Hugging Face et ModelScope.
Au niveau mondial, ce niveau d'ouverture est rare.
Pour l'industrie de la robotique, les possibilités offertes par une seule caméra viennent de s'élargir.
Références
- LingBot-Map. Dépôt de Hugging Face (huggingface.co/robbyant/lingbot-map)
- LingBot-Map. Page du modèle ModelScope (modelscope.cn/models/Robbyant/lingbot-map)
- LingBot-Map. Dépôt GitHub (github.com/Robbyant/lingbot-map)
- LingBot-Map : Streaming 3D Reconstruction with Geometric Context Attention. arXiv Preprint (arxiv.org/abs/2604.14141)
- Page d'accueil officielle de LingBot-Map (technology.robbyant.com/lingbot-map)

