
Respuesta corta:
Between DeepSeek V4 and OpenAI GPT-5.5, GPT-5.5 generally wins overall, especially in reasoning, coding, and complex task execution.
However, DeepSeek-V4 performs competitively—and even outperforms in some areas like HTML visualization—while being more efficient and lightweight.
Bottom line: GPT-5.5 is stronger overall, but DeepSeek-V4 offers impressive performance at much lower cost.
On April 24, 2026, something unusual happened—it felt like a “crazy Friday” for AI developers worldwide, the kind of day that might be remembered in tech history.
In the early hours, OpenAI dropped GPT-5.5 right on schedule, aiming once again to redefine the boundary of intelligence with sheer scale.
But before the shockwaves could settle, across the ocean, DeepSeek stepped in—launching DeepSeek-V4 on the same day, going straight into a head-to-head clash.
One side came in like a grand tech spectacle. The other? A near “table-flipping” counterattack from the open-source world.
The race toward AGI suddenly felt shorter.
GPT-5.5 vs DeepSeek-V4: A Direct Benchmark Battle
Puzzle Test: Truth, Lies, and Identity Reasoning
The first test looks simple, but it isn’t.
Four people A, B, C, D. Only one stole a gem.
- A: I didn’t steal it.
- B: C stole it.
- C: D stole it.
- D: B is lying.
Known conditions:
- Exactly two statements are true
- The thief always lies
- Non-thieves may lie or tell the truth
At first glance, it feels solvable—but actually, both B and C satisfy all conditions.
This is a trap question.
The real test is whether the model notices that the problem cannot be uniquely determined.
A stronger model should answer:
The thief cannot be uniquely determined. It could be B or C. The conditions are insufficient.
GPT-5.5 caught the trap quickly.
DeepSeek-V4, on the other hand, took much longer—its reasoning process stretched out significantly. But in the end, it still arrived at the correct conclusion.
The result is right. The process is just slower.
Mathematical Reasoning: Testing CoT Depth Limits
IMO-Level Game Problem
To push reasoning to the limit, they used a real International Mathematical Olympiad-level problem:
Alice and Bob play a game involving a parameter λ:
- Odd rounds: Alice picks xn, with total sum ≤ λn
- Even rounds: Bob picks xn, with sum of squares ≤ n
- If a player cannot move, they lose
- Infinite play = no winner
The task: determine for which values of λ each player has a winning strategy.
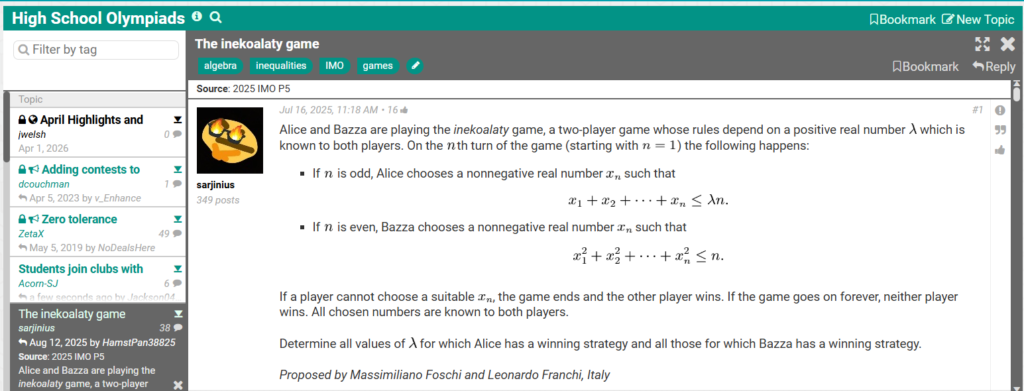
GPT-5.5 Performance
In deep reasoning mode, GPT-5.5:
- Produced the correct answer
- Took 2 minutes 51 seconds
- Showed clear, structured reasoning
- Delivered clean formatting
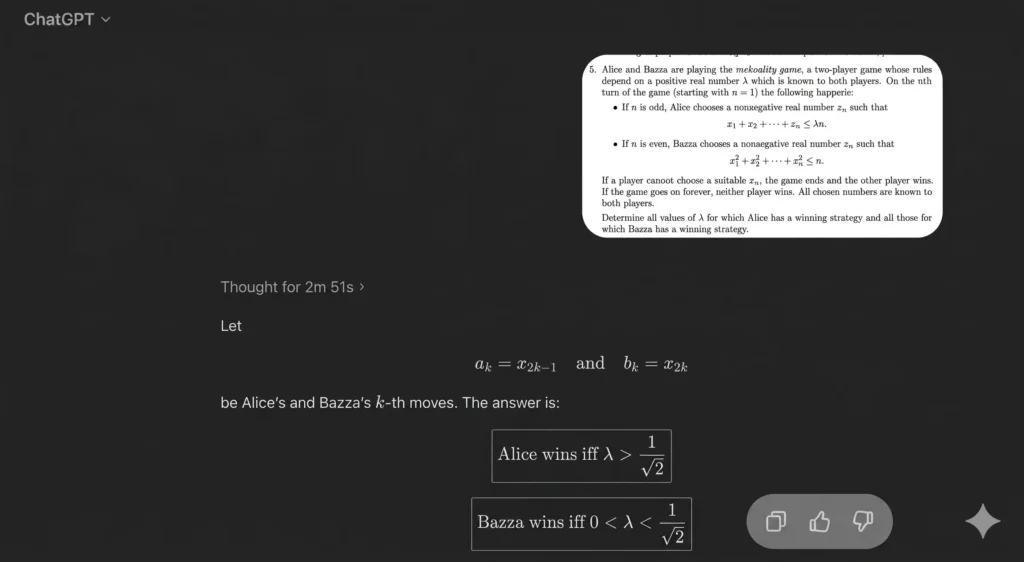
DeepSeek-V4 Performance
With expert mode enabled:
- Initially did not produce a clear answer
- Required continuation
- Eventually found the correct direction
- Successfully completed the proof
You can see it clearly: DeepSeek’s reasoning depth has improved a lot—but it’s still slower and less decisive. However, considering how DeepSeek starts updating frequently, this gap may not last long.
Visualization Ability: HTML Content Generation
Task: Build an Educational Webpage
Prompt: create an HTML page explaining human origins and biological evolution, with visuals.
- DeepSeek-V4 performed better here
- GPT-5.5 had formatting issues
This round goes to DeepSeek.

Game Development: 2D vs 3D Capability
Task: Build a Game Website
Requirements included:
- Dynamic graphics
- 3D interaction
- Collision detection
- Overall architecture
GPT-5.5:
- Completed quickly
- Delivered a working preview
- Stronger in rendering and architecture
DeepSeek-V4:
- Faster thinking this time
- But weaker final output
This round: GPT-5.5 wins clearly.
GPT-5.5 Feels More “Human”
Across early testers and developers, a consistent conclusion emerged:
GPT-5.5 dominates in:
- Programming
- Reasoning
- Long tasks
But what really stands out is something else—it feels more human.
- More expensive per token, but cheaper overall
- More powerful, yet better at conversation
- More autonomous, yet more controllable
It’s like the model didn’t just upgrade—it changed character.
Codex Mode: Beyond “AI-Assisted Programming”
GPT-5.5’s Codex mode essentially eliminates the idea of “AI-assisted programming.”
A tester gave it a full PRD and just one word: go
Hours later, the entire project was done.
More importantly, the workflow:
- Build
- Visually inspect
- Detect issues
- Iterate
It forms a closed loop, something rarely seen before.
Noam Brown commented that his productivity has never been higher—he can now write CUDA kernels and run experiments relying on GPT-5.5.
Strengths and Weaknesses
Strengths
- Backend development
- Complex debugging
- Large codebase understanding
- Spreadsheet tasks (state-of-the-art performance)
- Long-running research tasks (up to 31 hours autonomous execution)
AI is shifting from assistant → contractor.
Weaknesses
- Frontend design still behind top models
- Sometimes overly cautious
- May over-trigger unit testing
- Occasional messy SVG or layout shortcuts
Strong—but needs guidance.
Why GPT-5.5 Feels Different
It’s built on a new pretraining phase.
Pretraining defines the model’s fundamental capabilities before:
- Instruction tuning
- Tool use
- Reasoning scaffolds
Unlike GPT-5.4, which reused earlier foundations, GPT-5.5 introduces a new base.
That likely explains:
- Better coherence
- Higher efficiency
- More stable behavior
There are even hints it’s just an early checkpoint of a stronger future model.
Cost Paradox: More Expensive, Yet Cheaper
On paper, GPT-5.5 pricing is higher than 5.4.
Pero en la práctica:
- Uses fewer tokens for same tasks
- Completes tasks faster
- Requires fewer retries
Net effect: lower real-world cost
This matters a lot for AI agents—because token efficiency directly impacts scalability.
The Bigger Picture
GPT-5.5 didn’t create a dramatic “phase change.”
Instead, it:
- Smoothed rough edges
- Strengthened weak areas
- Became more reliable in messy real-world tasks
It’s not magic.
It won’t replace clear goals, context, or verification.
But for most people, most of the time, it simply works better.
Final Take: A More Complete Model
GPT-5.5 isn’t just about being smarter.
It’s about being:
- Broader
- Safer
- More consistent
It fills in the gaps.
And that, quietly, might matter more than anything else.

