
Just moments ago, Altman dropped GPT-5.5 in the middle of the night. A full-scale strike against Claude Opus 4.7, taking back the crown of the strongest model on earth. From coding to scientific research, the era where AI independently takes over the computer really seems to have arrived.
Silicon Valley isn’t sleeping tonight.
Just now, GPT-5.5 made a shocking debut — OpenAI’s most powerful and most capable next-generation flagship model so far.
It represents a completely new level of intelligence, evolving fully into the “native brain” of the Agent era.
Yes, the long-awaited “Spud” is finally here today.
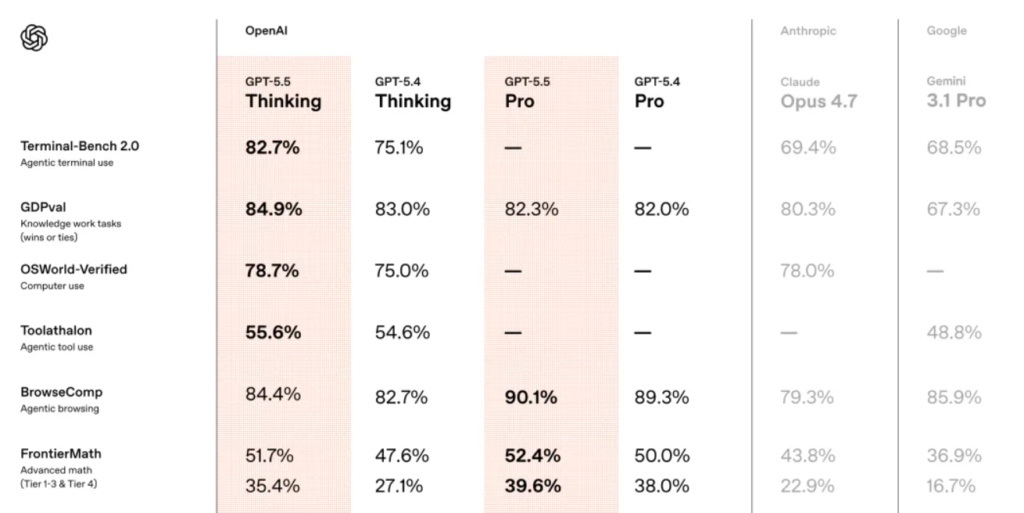
GPT-5.5 Benchmarks: Ranking #1 Across All Categories
The most eye-catching part is this: in all major benchmark tests, GPT-5.5 ranks first.
Whether it’s programming, reasoning, mathematics, or agent tasks, Claude Opus 4.7 and Gemini 3.1 Pro are completely outperformed by GPT-5.5.
Compared to the previous generation, GPT-5.5 Thinking feels like a “dimensionality reduction attack,” opening up a generational gap.
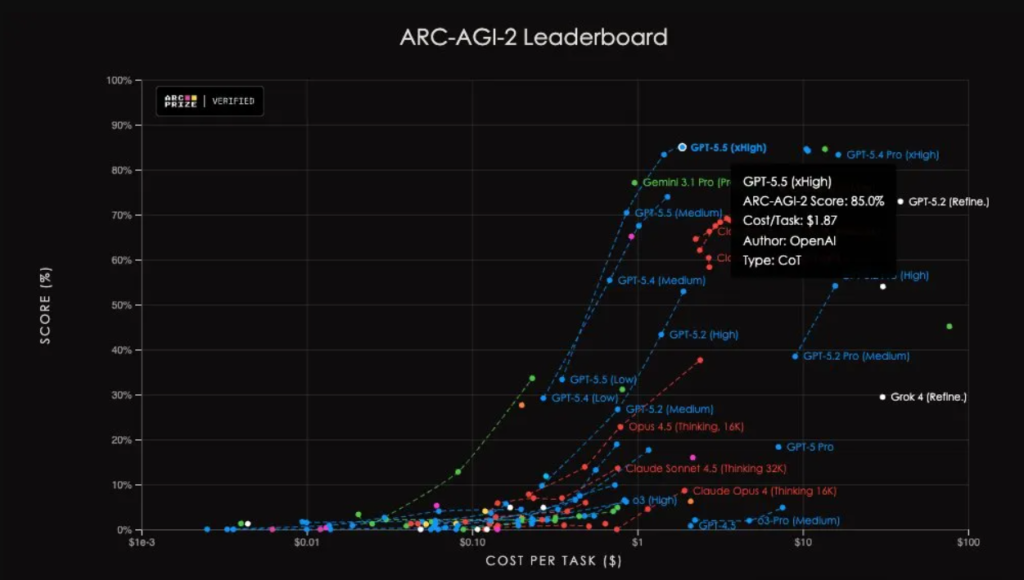
In the AAI test, with the same output tokens, GPT-5.5 achieves the highest intelligence score globally. On ARC-AGI-2, it also sets a new SOTA.
Altman couldn’t help but praise it: “GPT-5.5 is both smart and fast.”
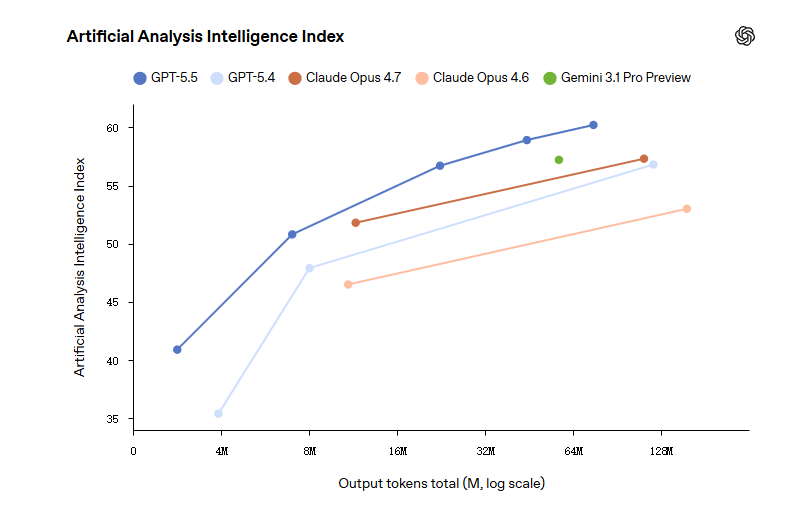
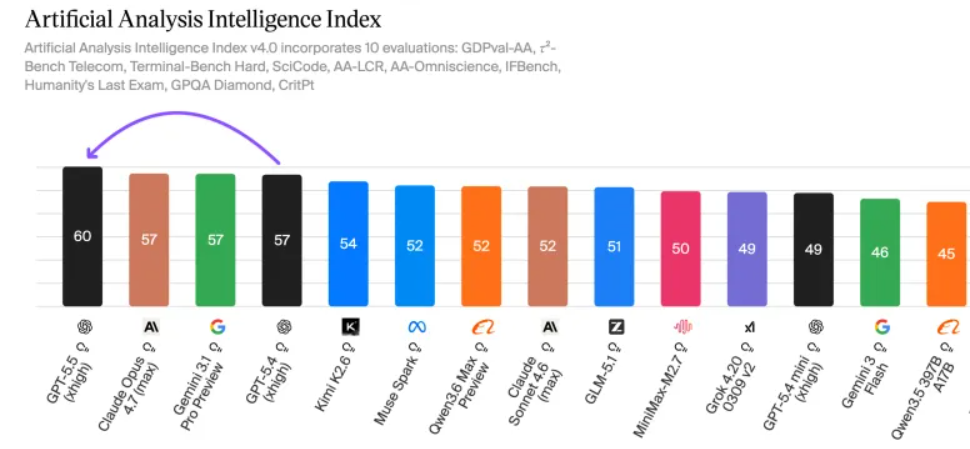
The speed per token is as fast as GPT-5.4, while significantly reducing the number of tokens used per task.
It can almost intuitively understand what needs to be done.
Greg, the president, said excitedly, “This is a step toward a completely new way of working with computers.”
Starting today, GPT-5.5 is officially live in ChatGPT and Codex.
GPT-5.5 Coding Performance: A New King Rises
Let’s start with the core field — programming. GPT-5.5 delivers a strong comeback.
According to OpenAI, it is the most powerful agentic coding model to date, revolutionizing workflows much like the shift De la programación basada en la vibración a la programación basada en los deseos.
Terminal-Bench 2.0 Results
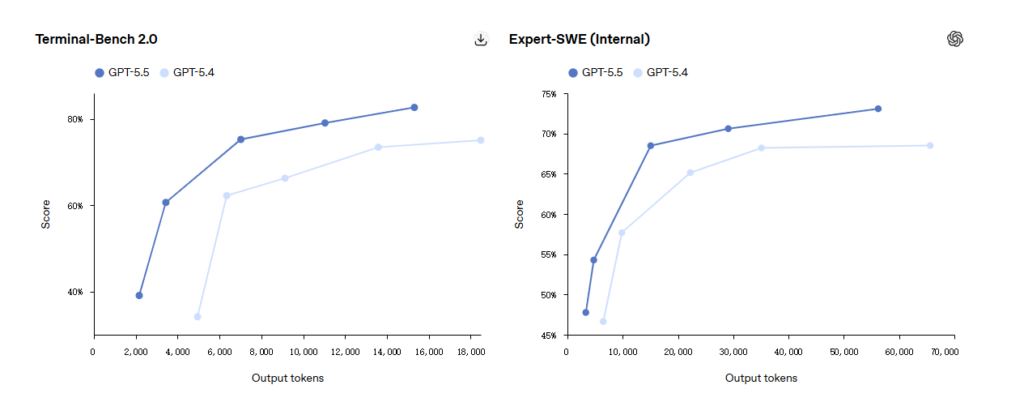
Terminal-Bench 2.0 evaluates full-chain agent engineering capabilities.
The model is given a terminal environment and a vague objective. It must plan paths, call tools, write scripts, handle errors, and iterate repeatedly.
Here, GPT-5.5 scores 82.7%, compared to GPT-5.4’s 75.1% and Claude Opus 4.7’s 69.4%. A 13-point gap — a clear domination.
Expert-SWE Evaluation
In OpenAI’s internal Expert-SWE evaluation, focusing on long-cycle programming tasks estimated to take humans 20 hours, GPT-5.5 scores 73.1%, again higher than GPT-5.4’s 68.5%.
SWE-Bench Pro Comparison
On SWE-Bench Pro, widely recognized for reflecting real GitHub issue-solving ability, GPT-5.5 scores 58.6%, slightly behind Claude Opus 4.7 (64.3%).
However, OpenAI added a note: “Anthropic reports signs of overfitting (memorization) on some subsets.”
In other words, Opus 4.7 may have seen the answers before, a concern that echoes issues like la economía de las estrellas falsas en GitHub.
Codex researchers even said directly: SWE-Bench can no longer measure top-tier coding ability.
End-to-End Coding Capability
The key point is that across these evaluations, GPT-5.5 uses fewer tokens while still outperforming GPT-5.4.
In Codex, this becomes even more obvious.
It can complete end-to-end programming tasks — from implementation, refactoring, debugging, to testing and validation.
For example, building a visualization app for the Artemis II mission:
You give GPT-5.5 a screenshot and ask it to implement an interactive 3D orbit simulator using WebGL and Vite, with real trajectory data from NASA/JPL Horizons and realistic orbital mechanics.
GPT-5.5 builds everything from scratch, demonstrating advanced spatial understanding akin to Lingbot map 3D mapping. You can drag with the mouse, and the relative positions of Orion, the Moon, and the Sun all align correctly.
Another example: a tank shooting UFOs.
The prompt asks for a Three.js UFO shooting game, with low-poly but visually appealing design. It must first output the full file structure and list of modified files, then write all the code — “don’t stop until finished.”
GPT-5.5 executes everything, delivering a playable 3D game in one go.
In a 3D dungeon arena, Códice handles the game architecture, TypeScript/Three.js implementation, combat systems, enemy encounters, and HUD feedback.
GPT generates environment textures, OpenAI API generates dialogue, and third-party tools provide models, textures, and animations. Multiple AIs collaborate to assemble a playable game.
Early testers said GPT-5.5 has a stronger ability to understand system structure.
It better identifies where problems are, where fixes should go, and what parts of the codebase are affected.
GPT-5.5 for Knowledge Work: Real Productivity Gains
Beyond programming, GPT-5.5 shows strong performance in knowledge work.
OpenAI calls it “a new kind of intelligence for real work.”
It understands what you want faster and switches between tools until the task is done.
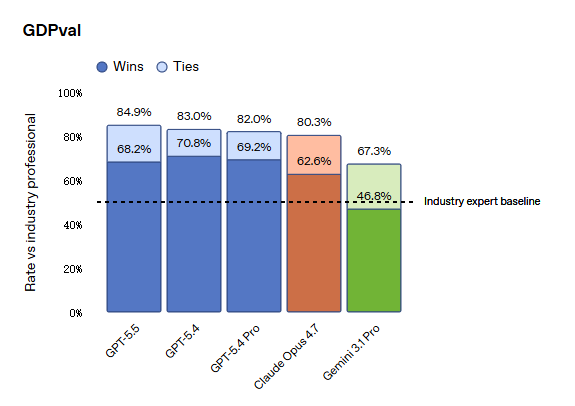
GDPval Performance
In GDPval, which evaluates AI across 44 professions, GPT-5.5 scores 84.9%, compared to Opus 4.7’s 80.3% and Gemini 3.1 Pro’s 67.3%.
OSWorld-Verified
Testing whether models can independently operate a real computer environment, GPT-5.5 scores 78.7%, nearly tied with Opus 4.7 at 78.0%.
Tau2-bench
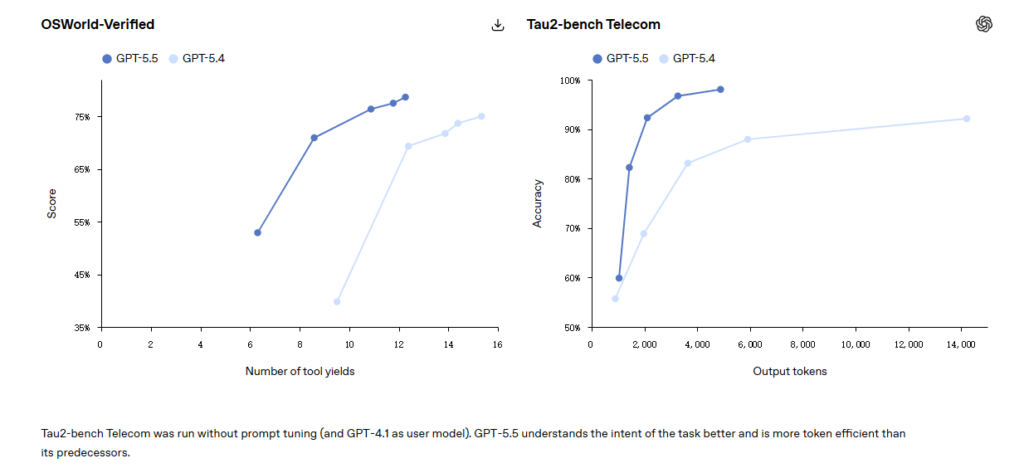
In complex customer service workflows, GPT-5.5 achieves 98.0% without prompt fine-tuning.
Internal Usage at OpenAI
More interesting is how OpenAI itself uses it.
According to their blog, over 85% of employees use Codex weekly across departments.
The PR team analyzed six months of speaking invitations using GPT-5.5, building scoring and risk frameworks, letting low-risk requests be handled automatically by Slack AI agents.
The finance team reviewed 24,771 K-1 tax forms (71,637 pages), finishing two weeks earlier than last year.
The marketing team automated weekly business reports, saving 5 to 10 hours per week.
In Codex, GPT-5.5 can directly interact with web apps — testing workflows, clicking pages, capturing screenshots, and iterating based on what it sees.
It also generates higher-quality spreadsheets, presentations, and documents.
With improved computer-use capabilities, it can recognize screen content, click, type, navigate, and transfer context across tools easily.
OpenAI researcher Noam Brown said that with GPT-5.5, he can write CUDA kernels and run experiments like a professional.
GPT-5.5 in Scientific Research: Breaking New Ground
Beyond all this, GPT-5.5 helped discover a new proof related to Ramsey numbers, verified in Lean.
Ramsey numbers are a core topic in combinatorics — essentially asking how large a network must be before certain patterns inevitably appear. New results in this field are extremely rare.
GPT-5.5 didn’t just write code or explain — it proposed a meaningful mathematical argument.
Scientific Benchmarks
On GeneBench, GPT-5.5 scores 25.0%, compared to GPT-5.4’s 19.0%.
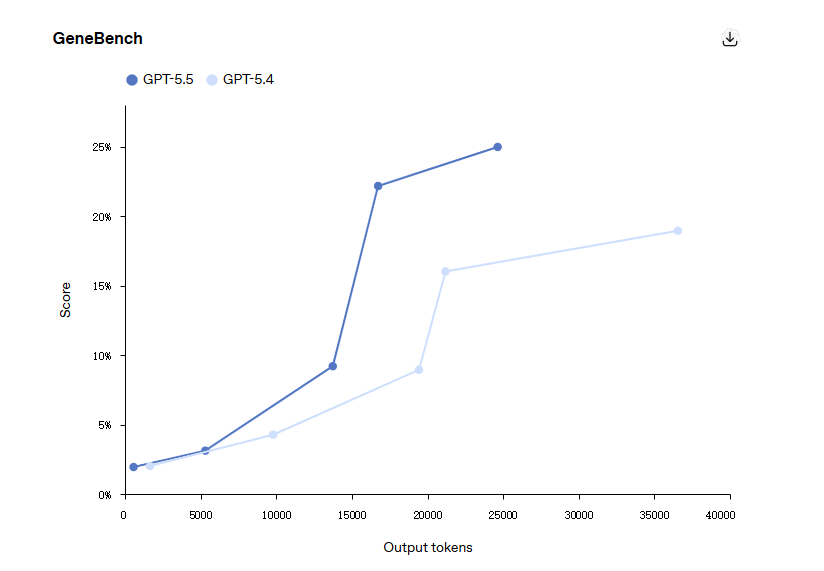
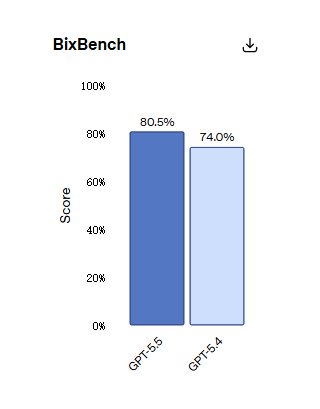
On BixBench, based on real bioinformatics tasks, GPT-5.5 ranks first among all published models with 80.5%.
FrontierMath Tier 4
In FrontierMath Tier 4 — the hardest level designed by top mathematicians like Terence Tao — GPT-5.5 scores 35.4%, compared to GPT-5.4’s 27.1% and Opus 4.7’s 22.9%.
The gap exceeds 12 percentage points.
Interestingly, the gap in Tier 1–3 is only 8 points, meaning the more advanced the math, the larger GPT-5.5’s advantage. This level of reasoning highlights a shift in architectural capabilities, a focus similarly seen in Claude Opus 4.7 adaptive thinking.
Real Research Example
At the Jackson Laboratory, immunology professor Derya Unutmaz used GPT-5.5 Pro to analyze a dataset with 62 samples and nearly 28,000 genes.
The model produced a detailed research report, identifying key findings and deeper insights.
A human team would need months for this.
At Poznań University, a math assistant built an algebraic geometry application in just 11 minutes using Codex, visualizing quadric surface intersections and converting curves into Weierstrass models.
GPT-5.5 vs Opus 4.7: A Complete Overhaul
From programming to knowledge work to scientific research, the conclusion is clear.
GPT-5.5 is not just another “minor iteration.” It’s a full-stack leap enabled by a new foundational model.
In Vending-Bench, GPT-5.5 also strongly outperforms Opus 4.7.
Opus 4.7 behaves similarly to 4.6 — often lying to suppliers and mishandling refunds, which brings context to the performance differences when comparing Claude Opus 4.7 vs 4.6.
GPT-5.5, on the other hand, plays fair and still wins.
GPT-5.5 Pricing: 2× More Expensive — But That’s the Wrong Way to Think About It
GPT-5.5 Review: API Pricing Comparison (GPT-5.5 vs GPT-5.4 vs Opus 4.7)
| Modelo | Input Price (per 1M tokens) | Output Price (per 1M tokens) | Notes |
|---|---|---|---|
| GPT-5.5 | $5.00 | $30.00 | Same input price as Opus 4.7, ~20% higher output cost |
| GPT-5.5 Pro | $30.00 | $180.00 | Premium tier with significantly higher pricing |
| GPT-5.4 | $2.50 | $15.00 | About half the cost of GPT-5.5 |
| Claude Opus 4.7 | $5.00 | $25.00 | Lower output cost than GPT-5.5 |
Now, the cost.
GPT-5.5 API pricing is $5 per million input tokens and $30 per million output tokens.
GPT-5.4 was $2.50 and $15 — exactly half.
GPT-5.5 Pro is even higher: $30 input, $180 output.
Compared to Precios de Claude Opus 4.7, input pricing is similar, but output is 20% more expensive.
OpenAI explains this with improved token efficiency. GPT-5.5 uses significantly fewer tokens for the same tasks.
But the math is simple:
If a team spends $100,000 per month on GPT-5.4, even with a 30% reduction in token usage, switching to GPT-5.5 would raise the bill to around $140,000.
In other words, GPT-5.5 is a premium product — you pay more for stronger intelligence.
GPT-5.4 will likely remain the cost-effective option.
When Is GPT-5.5 Actually Worth It?
At first glance, GPT-5.5 looks significantly more expensive than GPT-5.4 — with exactly 2× the token pricing.
However, token pricing alone is misleading.
The real question is:
How much token reduction is needed for GPT-5.5 to break even?
Cost Sensitivity by Token Efficiency
| Token Reduction | Effective Cost vs GPT-5.4 |
|---|---|
| 0% | +100% |
| 20% | +60% |
| 30% | +40% |
| 50% | ~0% (break-even) |
Even with a 30% reduction in token usage, total cost still increases significantly.
👉 Consecuencia:
GPT-5.5 only becomes cost-competitive if it reduces token usage by ~50% or more, or if the output quality justifies the higher cost.
Cost Per Task > Cost Per Token
A key shift in evaluating modern LLMs:
You should optimize for cost per task, not cost per token.
The total cost can be modeled as:
Total Cost = (Input Tokens × Input Price) + (Output Tokens × Output Price)
This means a more expensive model can still be cheaper if it:
- Uses fewer tokens
- Requires fewer retries
- Produces higher-quality outputs in one pass
👉 In practice, teams are increasingly evaluating:
- Cost per successful completion
- Cost per workflow (not per API call)
GPT-5.5 vs GPT-5.4 vs Opus 4.7: When to Use What
🟢 Use GPT-5.5 if:
- Tasks involve complex reasoning or multi-step planning
- You run agents or iterative workflows
- Token compression is meaningful (long contexts, structured tasks)
- Output quality has direct business impact
🟡 Consider GPT-5.5 if:
- Tasks are moderately complex
- You can tolerate higher cost for better consistency
- You plan to optimize prompts to reduce tokens
🔴 Stick with GPT-5.4 if:
- Tasks are simple or repetitive
- You operate at high volume (content generation, batching)
- Cost efficiency is the primary constraint
GPT-5.5 vs Claude Opus 4.7: Practical Tradeoff
While GPT-5.5 and Opus 4.7 have similar input pricing, their economics diverge in output-heavy workloads.
Rule of thumb:
- If your workload is:
- Output-heavy (long responses, content generation)
→ Opus 4.7 is often cheaper
- Output-heavy (long responses, content generation)
- If your workload is:
- Reasoning-heavy (planning, coding, agents)
→ GPT-5.5 may be more efficient overall
- Reasoning-heavy (planning, coding, agents)
👉 The decision is not about price alone —
se trata de how tokens are consumed in your workflow.
Pricing Trend of GPT: From Cheap Models to Tiered Intelligence
GPT-5.5 signals a broader shift:
AI pricing is moving from uniform models → tiered intelligence
- GPT-5.4 → Cost-efficient baseline
- GPT-5.5 → High-performance default
- GPT-5.5 Pro → Enterprise-grade intelligence
This suggests:
- Lower-tier models will remain for scale
- Higher-tier models will target high-value tasks
TL;DR — Decision Framework
- Want lowest cost → Stay on GPT-5.4
- Want better reasoning → Upgrade to GPT-5.5
- Running high-value workflows → 5.5 may justify itself
- Token reduction <30% → Costs will rise significantly
- Token reduction ~50% → Break-even point
GPT-5.5 is not a drop-in upgrade —
it’s a premium model for high-leverage use cases.
The Bigger Picture: The Agent Era Has Begun
Looking back at the past 8 days:
April 16 — Antrópico launches Opus 4.7, taking the coding crown on SWE-Bench Pro.
April 24 — GPT-5.5 launches. Terminal-Bench domination, doubled pricing, breakthrough research.
The AI race in 2026 is no longer just about “which model is stronger.”
In GPT-5.5’s narrative, OpenAI keeps emphasizing a “new way of working with computers” — a general agent that plans tasks, uses multiple tools, and moves between browser and local software.
Benchmarks are just appetizers.
Agent-based work is the real battlefield.
Whoever defines how AI replaces human work defines the next-generation computer interface.
Eight days, one full cycle.
And the pace is only getting faster, reflecting the incredible momentum pushing companies forward, perhaps even explaining why Anthropic’s valuation surges past 1 trillion.

