
Vor wenigen Augenblicken hat Altman mitten in der Nacht die GPT-5.5 abgesetzt. Ein Großangriff gegen Claude Opus 4.7, und erobert die Krone des stärksten Modells der Welt zurück. Von der Codierung bis zur wissenschaftlichen Forschung - die Ära, in der die KI den Computer selbstständig übernimmt, scheint wirklich gekommen zu sein.
Das Silicon Valley schläft heute Nacht nicht.
Soeben gab GPT-5.5 sein schockierendes Debüt - OpenAIs bisher leistungsstärkstes und leistungsfähigstes Flaggschiff der nächsten Generation.
Es stellt eine völlig neue Ebene der Intelligenz dar, die sich vollständig zum “nativen Gehirn” des Agentenzeitalters entwickelt.
Ja, der lang erwartete “Spud” ist heute endlich da.
GPT-5.5-Benchmarks: Rangliste #1 über alle Kategorien hinweg
Der auffälligste Teil ist dieser: In allen wichtigen Benchmark-Tests belegt GPT-5.5 den ersten Platz.
Ob Programmieren, logisches Denken, Mathematik oder Agentenaufgaben, Claude Opus 4.7 und Gemini 3.1 Pro werden von GPT-5.5 vollständig übertroffen.
Verglichen mit der vorherigen Generation fühlt sich GPT-5.5 Thinking wie ein “Dimensionalitätsreduktionsangriff” an, der eine Generationslücke aufreißt.
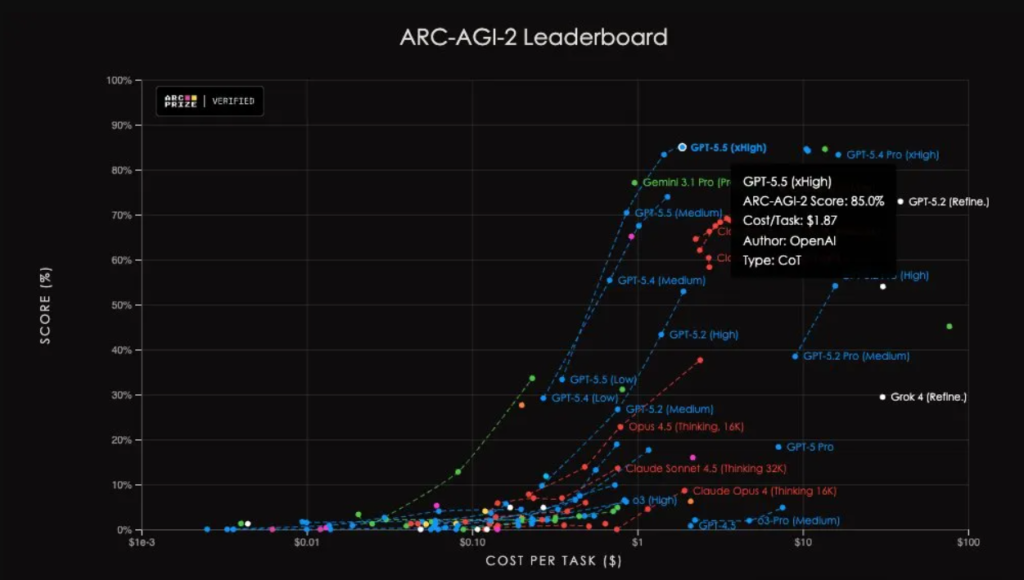
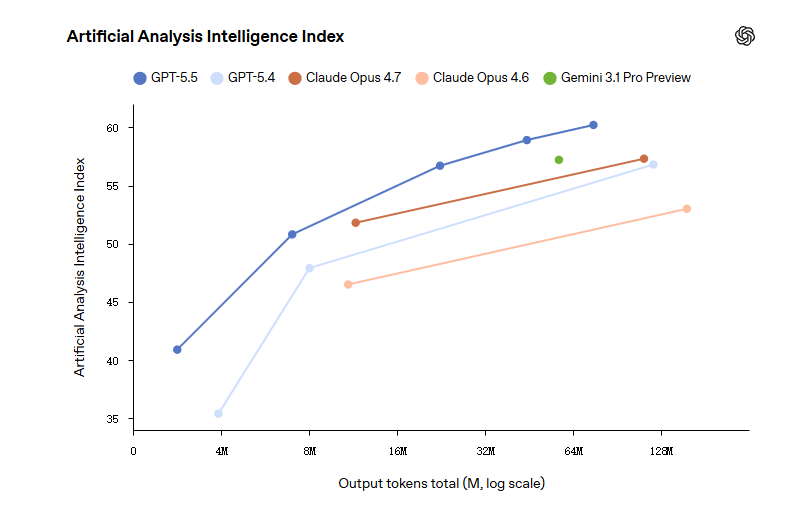
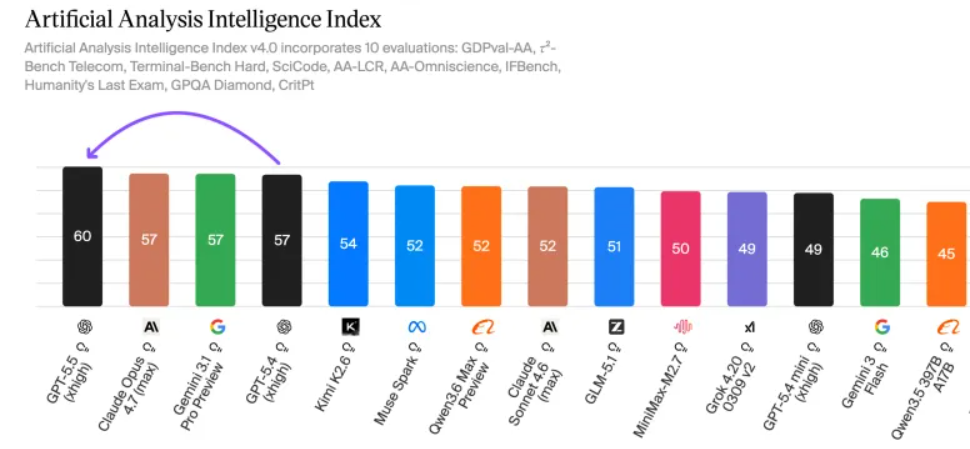
Im AAI-Test erreicht GPT-5.5 mit denselben Output-Tokens die höchste Intelligenzbewertung weltweit. Im ARC-AGI-2-Test stellt er außerdem einen neuen SOTA auf.
Altman konnte nicht anders, als es zu loben: “GPT-5.5 ist sowohl intelligent als auch schnell.”
Die Geschwindigkeit pro Token ist genauso hoch wie bei GPT-5.4, wobei die Anzahl der pro Aufgabe verwendeten Token deutlich reduziert wird.
Sie kann fast intuitiv verstehen, was zu tun ist.
Greg, der Präsident, sagte aufgeregt: “Dies ist ein Schritt in Richtung einer völlig neuen Art der Arbeit mit Computern.”
Ab heute ist GPT-5.5 offiziell verfügbar in ChatGPT und Codex.
GPT-5.5 Codierungsleistung: Ein neuer König erhebt sich
Beginnen wir mit dem Kernbereich - der Programmierung. GPT-5.5 liefert ein starkes Comeback.
Laut OpenAI handelt es sich dabei um das bisher leistungsfähigste agentenbasierte Codierungsmodell, das die Arbeitsabläufe ähnlich revolutionieren wird wie der Wandel der von der Vibe-Codierung zur Wunsch-Codierung.
Terminal-Bench 2.0 Ergebnisse
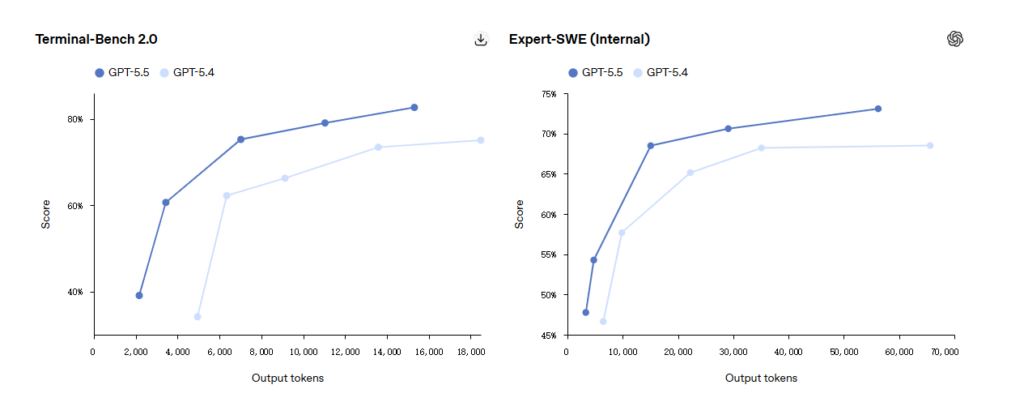
Terminal-Bench 2.0 bewertet die Fähigkeiten der Agentenentwicklung über die gesamte Kette.
Das Modell erhält eine Endumgebung und ein vages Ziel. Es muss Pfade planen, Werkzeuge aufrufen, Skripte schreiben, Fehler behandeln und wiederholt iterieren.
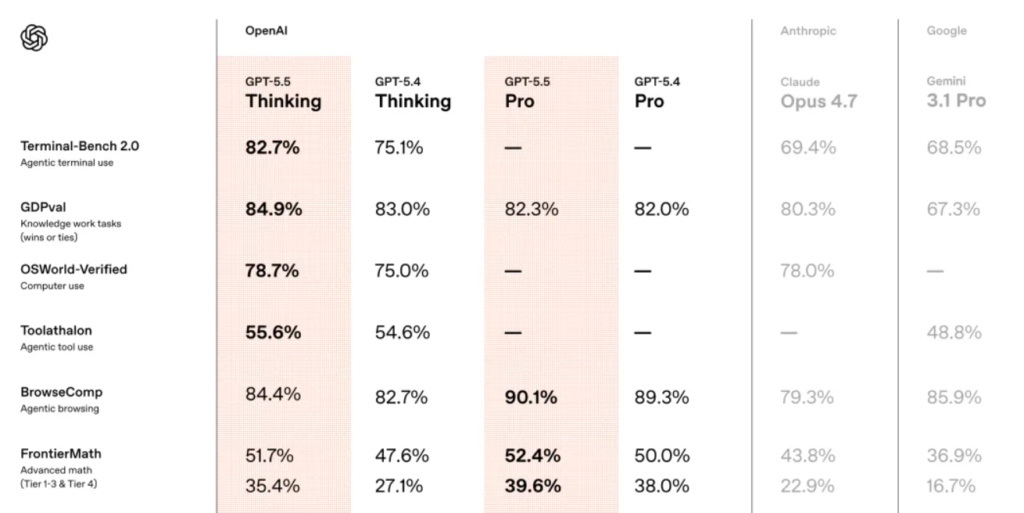
Hier erreicht GPT-5.5 einen Wert von 82,7%, verglichen mit 75,1% bei GPT-5.4 und Claude Opus 4.7’69,4%. Ein 13-Punkte-Abstand - eine klare Dominanz.
Experten-SWE-Bewertung
In OpenAIs interner Expert-SWE-Evaluierung, die sich auf langwierige Programmieraufgaben konzentriert, für die Menschen schätzungsweise 20 Stunden benötigen, erreicht GPT-5.5 73,1% und liegt damit erneut über dem Wert von GPT-5.4 (68,5%).
SWE-Bench Pro Vergleich
Im SWE-Bench Pro, der weithin dafür bekannt ist, die tatsächliche Fähigkeit zur Lösung von GitHub-Problemen widerzuspiegeln, erreicht GPT-5.5 einen Wert von 58,6% und liegt damit knapp hinter Claude Opus 4.7 (64,3%).
OpenAI fügte jedoch einen Hinweis hinzu: “Anthropic meldet Anzeichen von Überanpassung (Memorisierung) bei einigen Teilmengen.”
Mit anderen Worten: Opus 4.7 könnte die Antworten schon vorher gesehen haben, ein Anliegen, das an Themen wie die gefälschte Starwirtschaft auf GitHub.
Codex-Forscher sagten sogar direkt: SWE-Bench kann nicht mehr die besten Programmierfähigkeiten messen.
End-to-End-Codierfähigkeit
Der wichtigste Punkt ist, dass GPT-5.5 bei all diesen Bewertungen weniger Token verwendet und trotzdem besser abschneidet als GPT-5.4.
Im Codex wird dies noch deutlicher.
Es kann durchgängige Programmieraufgaben übernehmen - von der Implementierung, dem Refactoring, dem Debugging bis hin zu Test und Validierung.
Zum Beispiel die Entwicklung einer Visualisierungs-App für die Artemis II-Mission:
Sie geben GPT-5.5 einen Screenshot und bitten es, einen interaktiven 3D-Orbit-Simulator mit WebGL und Vite zu implementieren, mit echten Flugbahndaten von NASA/JPL Horizons und realistischer Orbitalmechanik.
GPT-5.5 baut alles von Grund auf neu auf und demonstriert ein fortgeschrittenes räumliches Verständnis, das dem von Lingbot-Karte 3D-Kartierung. Sie können mit der Maus ziehen, und die relativen Positionen von Orion, Mond und Sonne werden korrekt ausgerichtet.
Ein anderes Beispiel: ein Panzer, der UFOs abschießt.
Gefragt ist ein Three.js-UFO-Schießspiel mit Low-Poly, aber visuell ansprechendem Design. Es muss zuerst die vollständige Dateistruktur und die Liste der geänderten Dateien ausgeben, dann den gesamten Code schreiben - “nicht aufhören, bis es fertig ist.”
GPT-5.5 führt alles aus und liefert ein spielbares 3D-Spiel in einem Rutsch.
In einer 3D-Dungeon-Arena, Codex kümmert sich um die Spielarchitektur, die TypeScript/Three.js-Implementierung, die Kampfsysteme, die Gegnerbegegnungen und das HUD-Feedback.
GPT generiert Umgebungstexturen, OpenAI API generiert Dialoge, und Tools von Drittanbietern liefern Modelle, Texturen und Animationen. Mehrere KIs arbeiten zusammen, um ein spielbares Spiel zusammenzustellen.
Erste Tester bescheinigten GPT-5.5 eine bessere Fähigkeit, die Systemstruktur zu verstehen.
So lässt sich besser erkennen, wo Probleme bestehen, wo Korrekturen vorgenommen werden sollten und welche Teile der Codebasis betroffen sind.
GPT-5.5 für Wissensarbeit: Echte Produktivitätsgewinne
Über die Programmierung hinaus zeigt GPT-5.5 starke Leistungen bei der Wissensarbeit.
OpenAI nennt es “eine neue Art von Intelligenz für echte Arbeit”.”
Es versteht schneller, was Sie wollen, und wechselt zwischen den Werkzeugen, bis die Aufgabe erledigt ist.
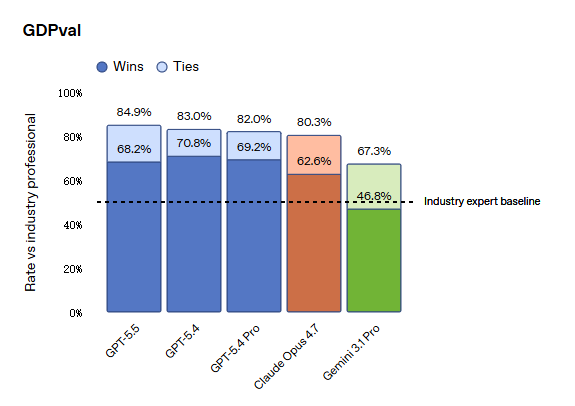
GDPval Leistung
In GDPval, das die KI in 44 Berufen bewertet, erreicht GPT-5.5 84,9%, verglichen mit 80,3% von Opus 4.7 und 67,3% von Gemini 3.1 Pro.
OSWorld-geprüft
Bei der Prüfung, ob die Modelle unabhängig voneinander eine reale Computerumgebung bedienen können, erreicht GPT-5.5 78,7% und liegt damit fast gleichauf mit Opus 4.7 (78,0%).
Tau2-Bank
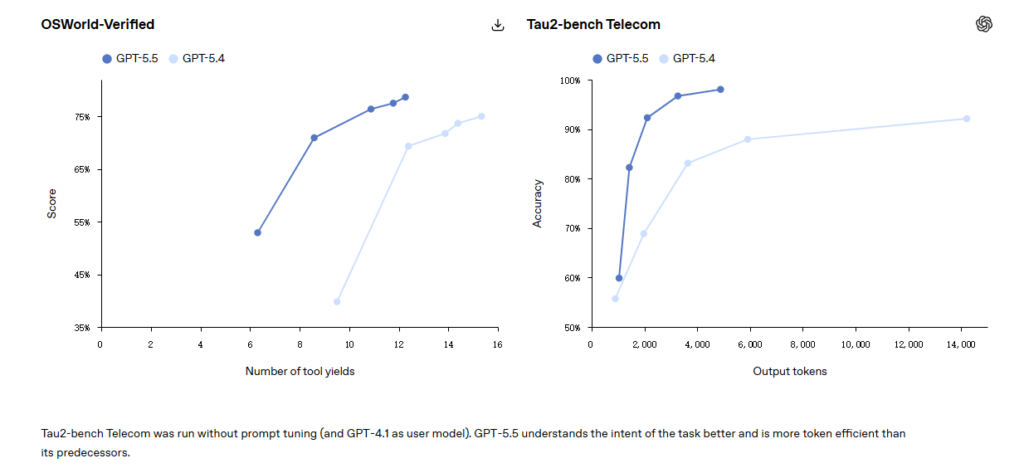
In komplexen Kundenservice-Workflows erreicht GPT-5.5 98,0% ohne sofortige Feinabstimmung.
Interne Verwendung bei OpenAI
Interessanter ist jedoch, wie OpenAI selbst es nutzt.
Laut ihrem Blog nutzen über 85% der Mitarbeiter Codex wöchentlich in allen Abteilungen.
Das PR-Team analysierte sechs Monate lang Einladungen zu Vorträgen mithilfe von GPT-5.5 und erstellte Scoring- und Risikoframeworks, sodass Anfragen mit geringem Risiko automatisch von Slack-KI-Agenten bearbeitet werden konnten.
Das Finanzteam prüfte 24.771 K-1-Steuerformulare (71.637 Seiten) und war damit zwei Wochen früher fertig als im Vorjahr.
Das Marketingteam automatisierte die wöchentlichen Geschäftsberichte und sparte so 5 bis 10 Stunden pro Woche.
In Codex kann GPT-5.5 direkt mit Webanwendungen interagieren - Arbeitsabläufe testen, Seiten anklicken, Screenshots aufnehmen und auf Basis der Ergebnisse iterieren.
Außerdem werden Tabellenkalkulationen, Präsentationen und Dokumente in besserer Qualität erstellt.
Dank verbesserter Funktionen für die Computernutzung kann es Bildschirminhalte erkennen, klicken, tippen, navigieren und den Kontext zwischen verschiedenen Tools problemlos übertragen.
OpenAI-Forscher Noam Brown sagte, dass er mit GPT-5.5 CUDA-Kernel schreiben und Experimente wie ein Profi durchführen kann.
GPT-5.5 in der wissenschaftlichen Forschung: Neue Wege beschreiten
Darüber hinaus trug GPT-5.5 zur Entdeckung eines neuen Beweises im Zusammenhang mit Ramsey-Zahlen bei, der in Lean verifiziert wurde.
Ramsey-Zahlen sind ein Kernthema der Kombinatorik - im Wesentlichen geht es um die Frage, wie groß ein Netzwerk sein muss, bevor bestimmte Muster unweigerlich auftreten. Neue Ergebnisse in diesem Bereich sind extrem selten.
GPT-5.5 hat nicht einfach nur Code geschrieben oder erklärt - es hat ein sinnvolles mathematisches Argument vorgeschlagen.
Wissenschaftliche Benchmarks
Im GeneBench erreicht das GPT-5.5 einen Wert von 25,0% im Vergleich zu 19,0% beim GPT-5.4.
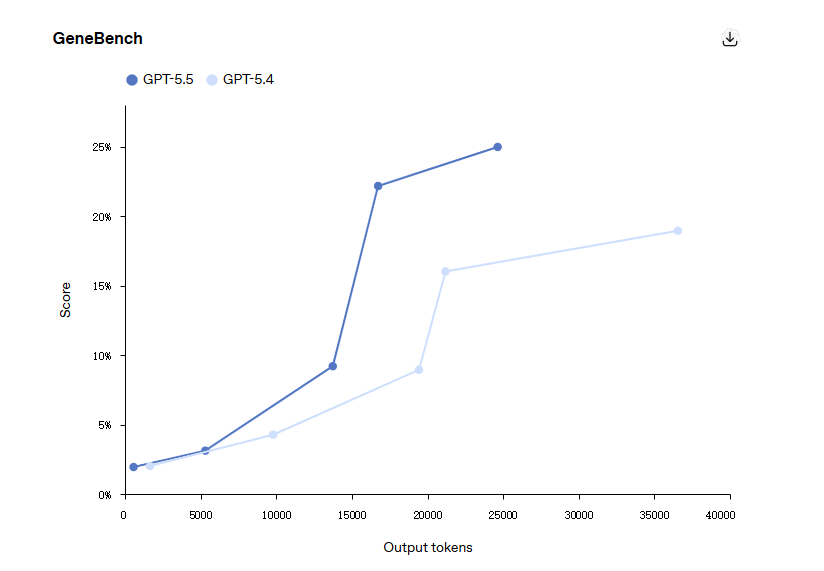
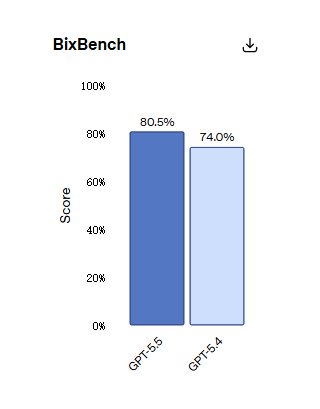
Auf der BixBench, die auf realen Bioinformatik-Aufgaben basiert, belegt GPT-5.5 mit 80,5% den ersten Platz unter allen veröffentlichten Modellen.
FrontierMath Stufe 4
In FrontierMath Tier 4 - der härtesten Stufe, die von Spitzenmathematikern wie Terence Tao entwickelt wurde - erreicht GPT-5.5 einen Wert von 35,4%, verglichen mit 27,1% bei GPT-5.4 und 22,9% bei Opus 4.7.
Der Abstand beträgt mehr als 12 Prozentpunkte.
Interessanterweise beträgt der Abstand in den Stufen 1-3 nur 8 Punkte, d. h. je fortgeschrittener die Mathematik, desto größer der Vorteil von GPT-5.5. Diese Argumentationsebene unterstreicht eine Verlagerung der architektonischen Fähigkeiten, ein Schwerpunkt, der in ähnlicher Weise bei Claude Opus 4.7 adaptives Denken.
Beispiel für echte Forschung
Am Jackson Laboratory analysierte der Immunologieprofessor Derya Unutmaz mit GPT-5.5 Pro einen Datensatz mit 62 Proben und fast 28.000 Genen.
Das Modell führte zu einem detaillierten Forschungsbericht, in dem die wichtigsten Erkenntnisse und tieferen Einsichten aufgezeigt wurden.
Ein menschliches Team würde dafür Monate brauchen.
An der Universität Poznań hat ein Mathe-Assistent mit Codex in nur 11 Minuten eine Anwendung für algebraische Geometrie erstellt, die quadratische Oberflächenschnittpunkte visualisiert und Kurven in Weierstraß-Modelle umwandelt.
GPT-5.5 vs. Opus 4.7: Eine komplette Überarbeitung
Von der Programmierung über die Wissensarbeit bis hin zur wissenschaftlichen Forschung - die Schlussfolgerung ist eindeutig.
GPT-5.5 ist nicht nur eine weitere “kleine Iteration”. Es ist ein umfassender Sprung, der durch ein neues Basismodell ermöglicht wird.
Auch im Vending-Bench schneidet GPT-5.5 deutlich besser ab als Opus 4.7.
Opus 4.7 verhält sich ähnlich wie 4.6 - es belügt oft die Lieferanten und behandelt die Erstattungen schlecht, was die Leistungsunterschiede beim Vergleich verdeutlicht Claude Opus 4.7 gegenüber 4.6.
GPT-5.5 hingegen spielt fair und gewinnt trotzdem.
GPT-5.5-Preise: 2× teurer - aber das ist der falsche Weg, darüber nachzudenken
GPT-5.5 Überprüfung: Vergleich der API-Preise (GPT-5.5 vs. GPT-5.4 vs. Opus 4.7)
| Modell | Input Preis (pro 1M Token) | Ausgabepreis (pro 1M Token) | Anmerkungen |
|---|---|---|---|
| GPT-5.5 | $5.00 | $30.00 | Gleicher Inputpreis wie Opus 4.7, ~20% höhere Outputkosten |
| GPT-5.5 Pro | $30.00 | $180.00 | Premiumstufe mit deutlich höheren Preisen |
| GPT-5.4 | $2.50 | $15.00 | Etwa die Hälfte der Kosten von GPT-5.5 |
| Claude Opus 4.7 | $5.00 | $25.00 | Niedrigere Produktionskosten als GPT-5.5 |
Und nun zu den Kosten.
GPT-5.5 API-Preise beträgt $5 pro Million Eingabe-Token und $30 pro Million Ausgabe-Token.
GPT-5.4 war $2.50 und $15 - genau die Hälfte.
GPT-5.5 Pro ist sogar noch höher: $30 Eingang, $180 Ausgang.
Verglichen mit Claude Opus 4.7 Preisgestaltung, Die Preise für den Input sind ähnlich, aber der Output ist 20% teurer.
OpenAI erklärt dies mit einer verbesserten Token-Effizienz. GPT-5.5 benötigt deutlich weniger Token für dieselben Aufgaben.
Aber die Rechnung ist einfach:
Wenn ein Team $100.000 pro Monat für GPT-5.4 ausgibt, würde ein Wechsel zu GPT-5.5 selbst bei einer Verringerung der Token-Nutzung um 30% die Rechnung auf etwa $140.000 erhöhen.
Mit anderen Worten: GPT-5.5 ist ein Premium-Produkt - Sie zahlen mehr für mehr Intelligenz.
GPT-5.4 wird wahrscheinlich die kostengünstigste Option bleiben.
Wann lohnt sich die GPT-5.5 tatsächlich?
Auf den ersten Blick sieht der GPT-5.5 deutlich teurer aus als der GPT-5.4 - mit genau 2× dem Token-Preis.
Die Preisgestaltung für Token allein ist jedoch irreführend.
Die eigentliche Frage ist:
Wie viel Token-Reduktion ist nötig, damit GPT-5.5 die Gewinnzone erreicht?
Kostensensitivität nach Token-Effizienz
| Token-Reduktion | Effektive Kosten gegenüber GPT-5.4 |
|---|---|
| 0% | +100% |
| 20% | +60% |
| 30% | +40% |
| 50% | ~0% (Kostendeckung) |
Auch mit einer 30% Verringerung des Tokenverbrauchs, Die Gesamtkosten steigen dennoch erheblich.
👉 Auswirkung:
GPT-5.5 wird nur dann wettbewerbsfähig, wenn es den Tokenverbrauch um ~50% oder mehr, oder ob die Qualität des Ergebnisses die höheren Kosten rechtfertigt.
Kosten pro Aufgabe > Kosten pro Token
Eine entscheidende Veränderung bei der Bewertung moderner LLMs:
Sie sollten für die Kosten pro Aufgabe optimieren, nicht für die Kosten pro Token.
Die Gesamtkosten können wie folgt modelliert werden:
Gesamtkosten = (Input-Token × Input-Preis) + (Output-Token × Output-Preis)
Das bedeutet, dass ein teureres Modell immer noch billiger sein kann. wenn es:
- Benötigt weniger Token
- Erfordert weniger Wiederholungsversuche
- Erzeugt qualitativ hochwertigere Ausgaben in einem Durchgang
👉 In der Praxis evaluieren die Teams zunehmend:
- Kosten pro erfolgreichem Abschluss
- Kosten pro Workflow (nicht pro API-Aufruf)
GPT-5.5 vs. GPT-5.4 vs. Opus 4.7: Wann wird was verwendet?
🟢 Verwenden Sie GPT-5.5, wenn:
- Die Aufgaben umfassen komplexe Argumentation oder mehrstufige Planung
- Sie laufen Agenten oder iterative Arbeitsabläufe
- Token-Kompression ist sinnvoll (lange Kontexte, strukturierte Aufgaben)
- Die Ausgabequalität hat direkte Auswirkungen auf das Geschäft
🟡 Ziehen Sie GPT-5.5 in Betracht, wenn:
- Die Aufgaben sind mäßig komplex
- Sie können höhere Kosten für bessere Konsistenz in Kauf nehmen
- Sie planen, Prompts zu optimieren, um Token zu reduzieren
🔴 Bleiben Sie bei GPT-5.4, wenn:
- Die Aufgaben sind einfach oder wiederholend
- Sie arbeiten bei hohes Volumen (Inhaltserstellung, Batching)
- Kosteneffizienz ist das wichtigste Kriterium
GPT-5.5 vs. Claude Opus 4.7: Praktischer Kompromiss
Während GPT-5.5 und Opus 4.7 ähnliche Input-Preise haben, unterscheiden sich ihre Wirtschaftlichkeit bei output-lastigen Workloads.
Faustformel:
- Wenn Ihre Arbeitsbelastung ist:
- Output-lastig (lange Antworten, Inhaltserstellung)
→ Opus 4.7 ist oft billiger
- Output-lastig (lange Antworten, Inhaltserstellung)
- Wenn Ihre Arbeitsbelastung ist:
- Denkintensiv (Planung, Codierung, Agenten)
→ GPT-5.5 könnte insgesamt effizienter sein
- Denkintensiv (Planung, Codierung, Agenten)
👉 Die Entscheidung ist nicht nur eine Frage des Preises -
es geht um wie Token in Ihrem Arbeitsablauf verbraucht werden.
Preisentwicklung bei GPT: Von Billigmodellen zu abgestufter Intelligenz
GPT-5.5 signalisiert eine breitere Verlagerung:
KI-Preise entwickeln sich weg von einheitlichen Modellen → abgestufte Intelligenz
- GPT-5.4 → Kosteneffiziente Basislinie
- GPT-5.5 → Leistungsstarker Standard
- GPT-5.5 Pro → Intelligenz auf Unternehmensniveau
Dies legt nahe:
- Die Modelle der unteren Klassen werden aus Größengründen beibehalten
- Höherwertige Modelle zielen auf Folgendes ab hochwertige Aufgaben
TL;DR - Entscheidungsrahmen
- Die niedrigsten Kosten wollen → Auf GPT-5.4 bleiben
- Bessere Argumentation wünschen → Aufrüstung auf GPT-5.5
- Hochwertige Arbeitsabläufe → Ausführung 5.5 kann sich rechtfertigen
- Token-Reduktion <30% → Die Kosten werden erheblich steigen
- Token-Reduktion ~50% → Break-even-Punkt
GPT-5.5 ist kein einfaches Upgrade -
Es ist ein Premium-Modell für hochwirksame Anwendungsfälle.
Das größere Bild: Die Ära der Agenten hat begonnen
Rückblick auf die vergangenen 8 Tage:
16. April. Anthropisch Startet Opus 4.7, und holt sich die Codierungskrone auf der SWE-Bench Pro.
24. April - GPT-5.5 wird eingeführt. Beherrschung der Terminal-Bench, verdoppelte Preise, bahnbrechende Forschung.
Beim KI-Wettlauf im Jahr 2026 geht es nicht mehr nur darum, welches Modell stärker ist.“
In der Beschreibung von GPT-5.5 betont OpenAI immer wieder eine ’neue Art, mit Computern zu arbeiten“ - ein allgemeiner Agent, der Aufgaben plant, mehrere Tools verwendet und sich zwischen Browser und lokaler Software bewegt.
Benchmarks sind nur Appetithäppchen.
Die agentenbasierte Arbeit ist das eigentliche Schlachtfeld.
Wer auch immer definiert, wie KI die menschliche Arbeit ersetzt, definiert die Computerschnittstelle der nächsten Generation.
Acht Tage, ein voller Zyklus.
Und das Tempo wird immer schneller, was die unglaubliche Dynamik widerspiegelt, die die Unternehmen vorantreibt und vielleicht sogar erklärt, warum Die Bewertung von Anthropic übersteigt 1 Billion.

