Ein chinesisches Team stellte LingBot-Map als Open Source zur Verfügung und schaffte mit einer gewöhnlichen Kamera eine 3D-Rekonstruktion mit 10.000 Bildern, die 1,2 Millionen Zuschauer im Internet anlockte.
Eine Kamera, die nur ein paar Dutzend Yuan kostet, schlägt LiDAR-Systeme im Wert von mehreren Zehntausend.
Unerwarteterweise hat das chinesische Team mit der frei zugänglichen LingBot-Map die weltweite Robotik-Gemeinschaft in Aufruhr versetzt.
Dies ist ein Streaming 3D-Rekonstruktionsfundamentmodell. Mit nur einer einzigen RGB-Kamera - kein LiDAR, kein Tiefensensor - erstellt es eine vollständige 3D-Karte in Echtzeit mit 20 FPS.

Das Erstaunlichste dabei ist, dass die Genauigkeit selbst nach 10.000 Bildern im Dauerbetrieb kaum abnimmt.
Ein KI-Forscher von Agility Robotics sagte: “Auf diesen Tag habe ich schon zu lange gewartet.”

Sogar Andrew Davison schaltete sich persönlich ein, um es zu loben:
Es sieht so aus, als ob hier ein beeindruckendes SLAM-Denken im Spiel war. Herzlichen Glückwunsch zu den Ergebnissen.
Davison äußert sich fast nie öffentlich zu bestimmten technischen Projekten. Wenn er aktiv etwas postet und das Wort “beeindruckend” verwendet, werden die Leute in diesem Bereich genauer hinschauen.

LingBot-Map beflügelt die SLAM-Welt - Branchenführer sagen “Endlich”
Mit LingBot-Map können Roboter wirklich die ganze Welt “verstehen”. Seine Open-Source-Veröffentlichung wurde von 1,2 Millionen Zuschauern verfolgt.
Mehrere Top-KOLs haben den Beitrag gepostet und geliked und damit in der gesamten Branche große Anerkennung erlangt.
Wie sieht also die von einem SLAM-Pionier gepriesene und von Forschern lang erwartete LingBot-Map in der Praxis aus?
Die vom Team veröffentlichten Praxistests geben die Antwort.
In einer Luftbildszene überfliegt die Kamera einen ganzen Stadtblock von oben. LingBot-Map rekonstruiert Gebäudefassaden, Dachstrukturen, Straßen und Straßenbäume in Echtzeit zu einer vollständigen 3D-Punktwolke - sogar Klimaanlagen auf dem Dach können unterschieden werden.
In einem Szenario zur Navigation in Innenräumen bewegt sich die Kamera von der Küche ins Wohnzimmer und durch einen Korridor. Die Beleuchtung und die Struktur ändern sich ständig, doch die rekonstruierte 3D-Karte mit mehreren Räumen ist exakt im Raum ausgerichtet, ohne Ausrichtungsfehler oder Geisterbilder zwischen den Räumen.
Ein lichtarmer Korridor wird zu einem extremen Test. Die Kamera bewegt sich durch einen fast pechschwarzen, schmalen Korridor. Herkömmliche Bildverarbeitungsmethoden versagen hier in der Regel, aber LingBot-Map liefert dennoch eine kohärente Korridorstruktur und eine stabile Trajektorie.
Noch interessanter ist, dass das Team LingBot-Map mit von LingBot-World generierten Videos im Zeichentrickstil fütterte und es trotzdem eine stabile 3D-Rekonstruktion durchführen konnte.
Die Eingabe ist eine KI-generierte virtuelle japanische Straße. Die Ausgabe ist eine 3D-Punktwolke mit genauen räumlichen Koordinaten. Die Kompatibilität zwischen den beiden Modellen stellt eine direkte Verbindung zwischen der Pipeline “virtuelle Welt → 3D-Raumverständnis” her.”
Der Vergleich der Flugbahnen macht es noch deutlicher.
Bei den Datensätzen Oxford Spires und Tanks & Temples überschneidet sich die von LingBot-Map vorhergesagte Flugbahn (orange) fast vollständig mit der Bodenwahrheit (blau), während die konkurrierenden Methoden TTT3R und WinT3R eine starke Abweichung aufweisen.
Das Innere von LingBot-Map - ein “Selektives Gedächtnis”-System
Die Hauptschwierigkeit bei der 3D-Rekonstruktion durch Streaming besteht darin, das Modell “beim Sehen bauen” zu lassen, ohne die Vergangenheit zu vergessen oder das Gedächtnis zu strapazieren.
Bei der herkömmlichen 3D-Rekonstruktion heißt es “erst erfassen, dann bearbeiten”.”
Bei der Streaming-Rekonstruktion muss das System beim Empfang neuer Bilder kontinuierlich lokalisieren und abbilden und dabei die Rechen- und Speicherkosten streng kontrollieren.
Bisherige Lösungen blieben in Kompromissen stecken.
Einige komprimierten zu stark und vergaßen nach und nach frühere Beobachtungen. Einige speicherten alle historischen Bilder im Cache, wodurch der Speicher linear mit der Sequenzlänge anstieg. Andere kombinierten Deep-Learning-Modelle mit herkömmlichen SLAM-Backends - mit guten Ergebnissen, aber manueller Abstimmung und mangelnder Echtzeitleistung.
LingBot-Map leiht sich eine strukturelle Erkenntnis aus dem klassischen SLAM.
Um Karten erstellen zu können, während sie sich in unbekannten Umgebungen bewegen, müssen Roboter ein räumliches Gedächtnis mit mehreren Granularitäten haben. Herkömmliches SLAM nutzt dazu handgefertigte geometrische Beschränkungen, was die Flexibilität einschränkt.
LingBot-Map verinnerlicht diese Struktur in den Aufmerksamkeitsmechanismus von Transformer und lässt das Modell lernen, was es sich merken und was es vergessen soll.
Dieser Mechanismus wird Geometric Context Attention (GCA) genannt und umfasst drei Gedächtnisschichten.
- Anker - erinnern Sie sich daran, “wo ich angefangen habe”.”
Die ersten Bilder dienen als Ankerbilder, die wie GPS-Basisstationen das Koordinatensystem und die Skalenbasislinie festlegen. Selbst bei Bild 10.000 weiß das Modell noch, wo sich Bild 1 befindet. - Pose-Referenz-Fenster - Erinnern Sie sich daran, “was um mich herum ist”.”
Es speichert die letzten Dutzend Bilder mit allen visuellen Informationen und erfasst dichte geometrische Details in der Nähe der aktuellen Position - wie der Blick durch die Windschutzscheibe eines Autos. - Flugbahngedächtnis - Erinnern Sie sich daran, “wo ich gewesen bin”.”
Entfernte Bilder enthalten nicht alle visuellen Details. Jedes Einzelbild wird auf nur 6 kompakte Token komprimiert, die die geometrischen Schlüsselinformationen der gesamten Flugbahn speichern. Wie bei einem Rückspiegel sieht man nicht jede Straßennummer, aber man weiß, woher man kommt.
Drei Speicherschichten klingen kompliziert, sind aber in der Praxis äußerst effizient.
Bei einem Video mit 10.000 Bildern speichert die kausale Standardaufmerksamkeit etwa 5 Millionen Token, während GCA nur etwa 70.000 verwendet. Jedes neue Bild fügt bei Standardmethoden etwa 500 Token hinzu, bei GCA jedoch nur 6 Token. Der Speicherzuwachs wird um etwa das 80-fache reduziert.
Deshalb kann LingBot-Map ultralange Videos mit konstantem Speicher verarbeiten, während andere nach ein paar tausend Bildern abstürzen.
LingBot-Map Trainingsstrategie und Benchmark-Ergebnisse
Das Team verwendete eine zweistufige Ausbildungsstrategie.
In der ersten Phase trainierten sie ein Basismodell auf 29 Datensätzen, die Innen-, Außen-, synthetische und reale Szenen abdeckten, um ein allgemeines geometrisches Verständnis aufzubauen.
In der zweiten Phase führten sie GCA ein und erhöhten die Anzahl der Ansichten schrittweise von 24 auf 320, so dass das Modell zunächst kurze Sequenzen und dann lange Trajektorien lernen konnte.
In der Bewertung werden die Ergebnisse für fünf Benchmarks dargestellt.
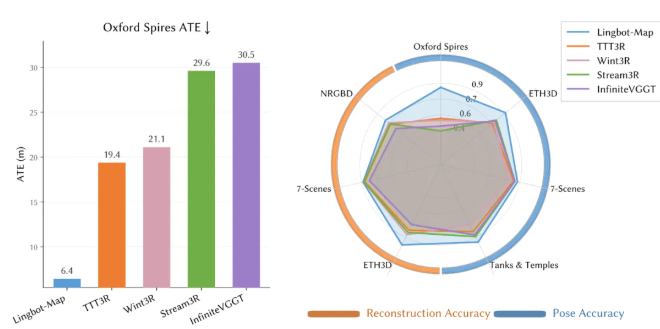
Auf Oxford Spires (große gemischte Indoor-Outdoor-Trajektorien an der Universität Oxford) erreicht LingBot-Map einen ATE-Fehler von 6,42 Metern, verglichen mit 18,16 Metern für den zweiten Platz - fast 3× besser.
Diese Genauigkeit übertrifft sogar Offline-Methoden, die alle Bilder auf einmal verarbeiten (12,87), und traditionelle iterative Optimierungsmethoden (10,52).
Bei einer Skalierung von 320 Frames auf 3.840 Frames steigt der ATE nur von 6,42 auf 7,11 und zeigt damit fast keine Verschlechterung mit der Sequenzlänge.
Auf ETH3D (mit lasergescannter Bodenwahrheit) erreicht die Rekonstruktion F1 einen Wert von 98,98 und verbessert sich damit um mehr als 21 Prozentpunkte gegenüber dem zweiten Platz (77,28).
Bei Panzern und Tempeln (große Bauwerke im Freien) liegt der ATE bei 0,20 Metern gegenüber 0,76 Metern auf dem zweiten Platz.
Bei 7-Szenen (RGB-D in Innenräumen) beträgt der ATE 0,08 Meter - das beste Ergebnis.
Was LingBot-Map für die Robotik bedeutet
Die akademische Welt schaut auf ATE und F1, aber die Robotikunternehmen berechnen eine andere Gleichung.
Erstens die Hardwarekosten.
Ein industrietaugliches LiDAR kostet Tausende bis Zehntausende von Dollar. Rechnet man IMUs, Kalibrierungs-Toolchains und Softwareanpassungen hinzu, kann allein die Wahrnehmung ein Drittel der gesamten Roboterkosten ausmachen.
LingBot-Map benötigt nur eine Kamera, die ein paar Dutzend Yuan kostet.
Bei Kategorien wie Heimservice-Robotern und langsamen Lieferfahrzeugen, bei denen die Preissensibilität extrem hoch ist, ist die Entfernung von LiDAR viel wichtiger als das Hinzufügen eines weiteren Chips.
Die zweite ist die autonome Navigation über lange Zeiträume.
Roboter, die in großen Logistikzentren oder städtischen Umgebungen eingesetzt werden, müssen stundenlang ununterbrochen laufen. Herkömmliche Systeme stoßen bei langen Sequenzen an ihre Speichergrenzen.
Die Fähigkeit von LingBot-Map, mehr als 10.000 Bilder mit konstantem Speicher zu verarbeiten, macht eine lange Autonomie in großen Räumen möglich.
Ein weiterer Aspekt ist die geschickte Manipulation.
Dies stellt eine Verbindung zu LingBot-Depth her, das bereits früher als Open Source veröffentlicht wurde.
Wenn Roboter versuchen, durchsichtiges Glas oder reflektierende Metallbehälter zu greifen, sind herkömmliche Tiefenkameras fast “blind”. Diese Materialien reflektieren keine zuverlässigen Signale, was zu großen Löchern in den Tiefenkarten führt.
LingBot-Depth verwendet Masked Depth Modeling (MDM), um dieses Problem zu lösen.
Während des Trainings werden Teile der Tiefenkarte absichtlich maskiert, um das Modell zu zwingen, Abstände aus RGB-Texturen und Konturen abzuleiten.
Das Ergebnis ist eine Spitzenleistung bei Benchmarks wie NYUv2 und ETH3D, wobei die Tiefengenauigkeit sogar Tiefenkameras in Industriequalität übertrifft.
Das Modell wurde vom Tiefenerkennungslabor von Orbbec zertifiziert, und beide Seiten sind eine strategische Partnerschaft zur Entwicklung von Tiefenkameras der nächsten Generation eingegangen. In Praxistests erzielte es eine Erkennungsrate von 50% auf transparenten Lagerboxen.
LingBot-Depth sorgt dafür, dass man sieht, wie weit jedes Pixel entfernt ist, während LingBot-Map dafür sorgt, dass man die gesamte 3D-Szene in Echtzeit versteht.“
Zusammen schließen sie den Kreislauf der räumlichen Wahrnehmung für Roboter.
Roboterarme, die Glasbecher in der Küche, Reagenzgläser im Labor oder reflektierende Metallbehälter im Lager ansteuern, verfügen jetzt über zuverlässige 3D-Raumbezüge.
LingBot-Map vervollständigt das Puzzle der verkörperten KI

Im Großen und Ganzen ist die Freigabe von LingBot-Map kein isoliertes Ereignis, sondern ein wichtiger Meilenstein in einer klaren Roadmap für verkörperte KI.
Im Januar stellte das Team während der Embodied Intelligence Evolution Week“ vier Modelle zur Verfügung.”
LingBot-Depth behandelt die Tiefenwahrnehmung.
LingBot-VLA ist ein verkörpertes, großes Modell, das im GM-100-Benchmark der Shanghai Jiao Tong University rekordverdächtige Erfolgsquoten in der realen Welt erzielt.
LingBot-World zielt auf Google Genie 3 ab und ermöglicht Echtzeit-Interaktion bei 16 FPS.
LingBot-VA führte eine autoregressive gemeinsame Modellierung von Video und Aktionen ein und verbesserte die Erfolgsraten bei realen Aufgaben um 20% gegenüber Pi0.5.
Aber etwas fehlte.
Die Tiefenschätzung liefert “Punkte” auf Bildebene, während die 3D-Kartierung kontinuierliche “Oberflächen” liefert. Die Zwischenschicht - räumliches Verständnis in Echtzeit - fehlte.
LingBot-Map füllt genau diese Lücke.
Jetzt bildet der gesamte verkörperte KI-Stapel einen geschlossenen Kreislauf:
Die Welt sehen (Tiefe) → Den Raum verstehen (Karte) → Die Physik simulieren (Welt) → Entscheiden und handeln (VLA/VA)
Jede Komponente in dieser Kette ist unter der Apache 2.0-Lizenz als Open Source verfügbar, wobei Code, Gewichte und technische Berichte auf Plattformen wie Hugging Face und ModelScope veröffentlicht werden.
Weltweit ist dieses Maß an Offenheit selten.
Für die Robotikindustrie hat sich das Spektrum der Möglichkeiten einer einzelnen Kamera gerade erweitert.
Referenzen
- LingBot-Map. Hugging Face Repository (huggingface.co/robbyant/lingbot-map)
- LingBot-Map. ModelScope Modellseite (modelscope.cn/models/Robbyant/lingbot-map)
- LingBot-Map. GitHub-Repository (github.com/Robbyant/lingbot-map)
- LingBot-Map: Streaming 3D Reconstruction with Geometric Context Attention. arXiv Preprint (arxiv.org/abs/2604.14141)
- LingBot-Map Offizielle Homepage (technology.robbyant.com/lingbot-map)

