
Claude Opus 4.7 Reclaims Top Rankings in AI Benchmarks
This week, Anthropic released Claude Opus 4.7.
It has climbed back to the top in two of the most closely watched public benchmarks.
On Artificial Analysis’s overall intelligence leaderboard, Opus 4.7 scored 57, up from 53 for Opus 4.6, placing it firmly in the top tier.
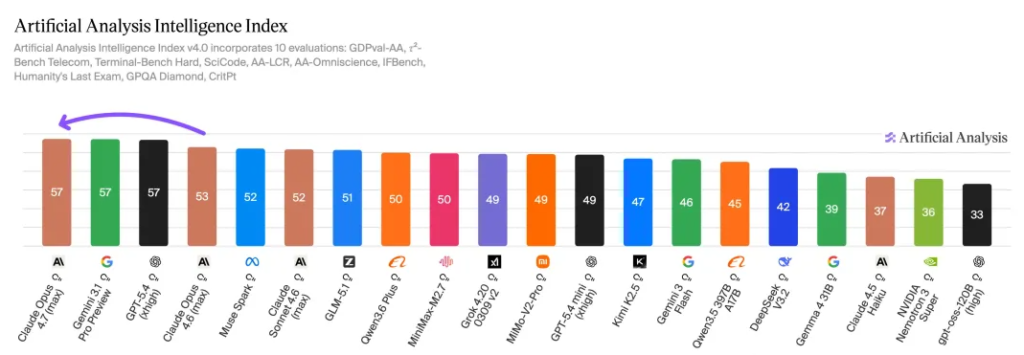
On Arena.ai’s latest Code Arena results, Opus 4.7 ranked first with a score of 1583—34 points higher than Opus 4.6 Thinking at 1549. It also led the nearest non-Anthropic model by a noticeable margin, and took first place in both the React and HTML subcategories.
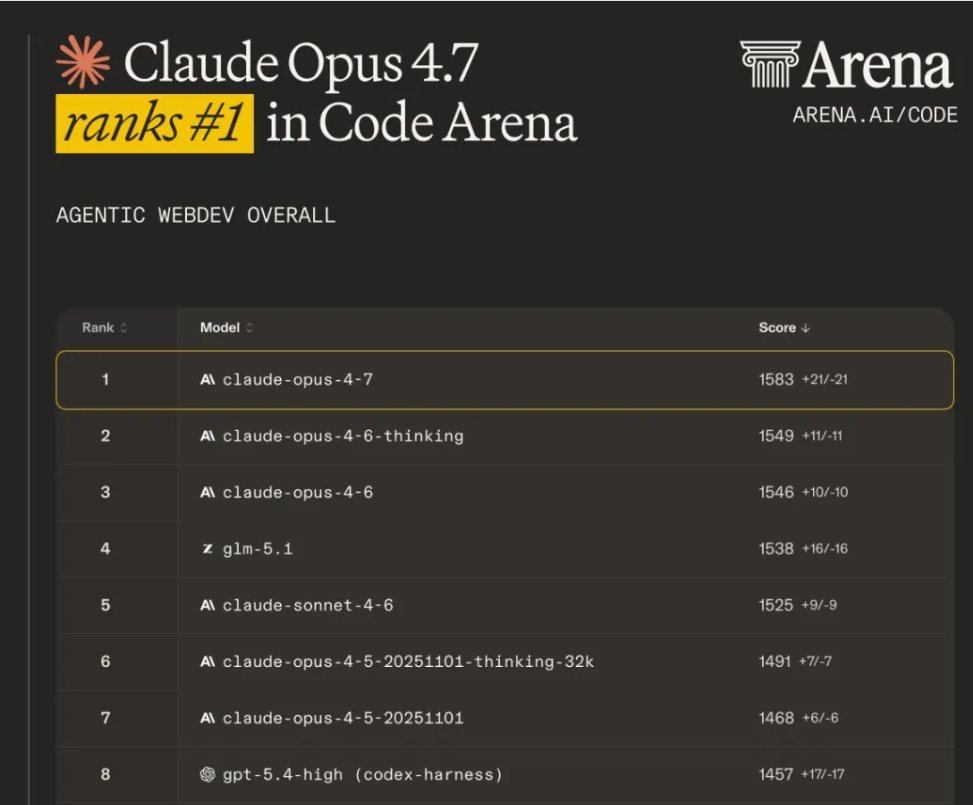
Benchmark Results: How Claude Opus 4.7 Compares to Opus 4.6
The significance of this round of rankings feels less like a breakthrough—and more like a market recalibration.
Over the past two years, the large model industry has been obsessed with pushing capability boundaries: who has more parameters, who can reason longer, who demos better, who looks closer to that ever-distant AGI.
Why Enterprise AI Needs Are Changing in 2026
But by 2026, the criteria from enterprise customers have shifted.
There are fewer questions about which model is the most well-rounded genius, and more about something far more practical:
Can it plug into systems?
Can it fit into workflows?
Can it reliably get the job done?
The score improvements in Opus 4.7 land squarely on this new standard.
Claude Opus 4.7 Performance Gains in Real-World Workflows
Anthropic’s own disclosed metrics point in a very consistent direction.
Across 93 internal coding benchmarks, Opus 4.7 improved task completion rates by 13% compared to Opus 4.6.
On CursorBench, performance increased from 58% to 70%.
In Notion’s multi-step workflow tests, overall effectiveness improved by 14%, while tool-calling errors dropped to one-third of previous levels.
Even Anthropic’s customer feedback highlights the same themes:
autonomy, fewer errors, and the ability to keep going when tools fail.
Individually, none of these numbers look dramatic. But taken together, they tell a clear story.
From Chat to Execution: The Shift Toward Workflow AI
The improvements in Opus 4.7 are concentrated in the hardest-to-scale—and most commercially decisive—capabilities: long task execution, multi-step coordination, tool reliability, and restraint when information is incomplete.
Single-turn question answering is starting to feel like a demo effect.
Stable performance across long workflows is what companies are actually willing to pay for.
Models today need to read codebases, modify multiple files, handle dependency errors, recover from failures, and still know when to stop.
Most system failures don’t come from getting one step wrong. They come from workflows gradually breaking down as they get longer—until a human has to step back in and finish the job.
Anthropic’s Strategy: Building AI for Production Systems
Anthropic’s strategy over the past year has consistently focused on this.
Instead of optimizing for the most immediately visible improvements in chat experience, it has been pushing the model toward becoming an “execution unit.”
Coding, knowledge retrieval, document review, legal research, financial analysis—these are low-tolerance, high-value tasks that naturally align with enterprise purchasing.
The companies Anthropic highlights this time—Cursor, Notion, Rakuten, CodeRabbit, Warp, Vercel, XBOW—are all tied to specific workflows, not broad consumer scenarios.
That’s the most interesting part of the Opus 4.7 release.
Anthropic has never been chasing the loudest user entry points.
It’s going after where enterprise budgets actually concentrate.
AI Model Competition: Claude vs OpenAI vs Google
OpenAI still commands the most public attention.
Google still controls the platform and infrastructure layer.
The open-source ecosystem continues to pressure margins with lower costs.
Anthropic’s path has always been narrower—and clearer.
It’s aiming for workflows where ROI can already be calculated.
Once a model enters processes like code generation, document handling, financial analysis, or legal research, the outcome isn’t a one-time “wow moment.” It becomes measurable: reduced labor, faster turnaround, lower error rates.
And that’s where pilots turn into procurement—and procurement turns into renewals.
What Claude Opus 4.7 Means for Enterprise AI Adoption
Being at the top of the leaderboard still matters, but it’s no longer decisive.
Arena’s breakdown shows Opus 4.7 leading in Overall, Expert, and Coding, with improvements in Creative Writing as well.
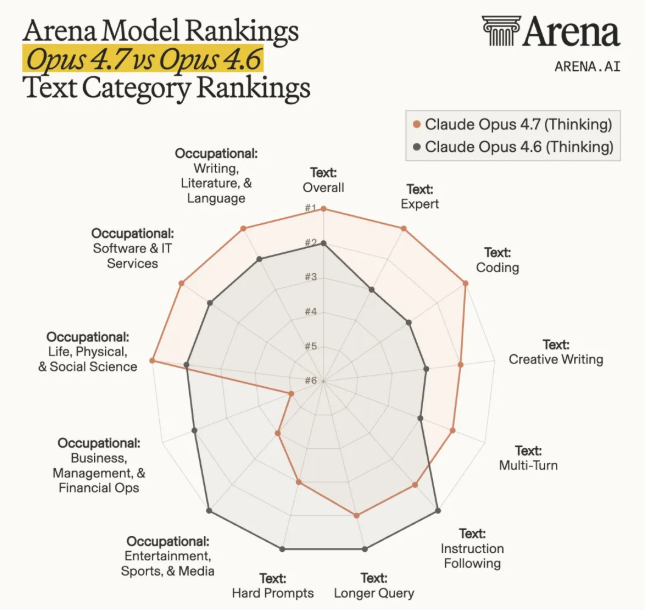
But in some categories, Opus 4.6 still performs better.
That actually says more about where the competition is now.
The race between frontier models is no longer about generational leaps. It’s about differences in task structure and capability mix.
The market isn’t waiting for a single model that does everything. It’s looking for the right model for each task.
Some models will be stronger in engineering tasks.
Others in multimodal workflows.
Others will win on price.
The rankings will keep shifting.
Why Claude Opus 4.7 Signals a Shift Toward Reliable AI
That’s also why the timing of Opus 4.7 matters.
Around its release, another recurring topic in the market has been speculation about OpenAI’s next model, GPT-5.5. Even prediction markets like Polymarket have seen increased activity.
For now, though, most of that remains expectation.
What actually enters enterprise evaluation pipelines are models that are already released, benchmarked, and ready to integrate.
Anthropic doesn’t need to prove that Opus 4.7 will be the strongest model six months from now.
What it needs—and what it’s doing—is positioning itself back onto the shortlist for enterprise buyers and platform partners before the next major wave of model releases arrives.
And it’s doing so with something very concrete: a model that can be evaluated, integrated, and purchased.
At this point, that case is already clear.
The benchmark results, coding performance, improvements in long-task execution, and reduced tool errors all come together into a strong signal:
Anthropic has delivered a flagship model that is better suited for production systems.
For enterprise customers, that signal matters far more than any grand narrative about the future.
Procurement doesn’t happen because one company tells a better story.
It happens because another company is more likely to deliver reliable results.
And what Anthropic is really aiming for is pricing power in the next phase of the enterprise AI market.
Frequently Asked Questions
What is Claude Opus 4.7?
Claude Opus 4.7 is Anthropic’s latest flagship AI model, designed for complex workflows, coding, and long-task execution. It improves on Opus 4.6 with higher benchmark scores and better tool-use reliability.
How good is Claude Opus 4.7 compared to Opus 4.6?
Claude Opus 4.7 outperforms Opus 4.6 across multiple benchmarks, including coding and workflow tasks, with improvements in task completion, multi-step reasoning, and significantly fewer tool-calling errors.
Is Claude Opus 4.7 better than GPT models?
Claude Opus 4.7 is highly competitive, especially in coding and long workflow execution. While GPT models may lead in general use or ecosystem, Opus 4.7 is stronger in reliability and structured tasks.
What makes Claude Opus 4.7 different from other AI models?
Claude Opus 4.7 focuses on execution rather than just conversation. It is designed to handle long, multi-step tasks, maintain stability across workflows, and reduce errors during tool interactions.
What are the main use cases of Claude Opus 4.7?
Claude Opus 4.7 is commonly used for coding, document analysis, legal research, financial workflows, and other enterprise tasks that require accuracy, consistency, and multi-step execution.
Why is Claude Opus 4.7 important for enterprise AI?
Claude Opus 4.7 improves reliability in real-world workflows, which is critical for enterprise adoption. Its ability to reduce errors and complete long tasks makes it more suitable for production systems.
Does Claude Opus 4.7 support real-world workflows?
Yes. Claude Opus 4.7 is specifically optimized for real-world workflows, including tool usage, multi-step reasoning, and system integration, making it more practical for enterprise deployment.
Still have questions about Claude Opus 4.7? Explore more AI model insights on DeepInsightAI.

