Un equipo chino puso en marcha LingBot-Map y, con sólo una cámara normal, consiguió una reconstrucción en 3D de 10.000 fotogramas, que atrajo a 1,2 millones de espectadores en Internet.
Una cámara que cuesta sólo unas decenas de yuanes supera a sistemas LiDAR que valen decenas de miles.
Inesperadamente, el LingBot-Map de código abierto del equipo chino encendió directamente la comunidad robótica mundial.
Se trata de un modelo de cimentación de reconstrucción 3D en streaming. Con una sola cámara RGB -sin LiDAR ni sensor de profundidad- construye un mapa 3D completo en tiempo real a 20 FPS.

Lo más sorprendente: incluso después de funcionar continuamente durante 10.000 fotogramas, la precisión apenas disminuye.
Un investigador de IA de Agility Robotics dijo: “Llevo demasiado tiempo esperando este día”.”

Incluso Andrew Davison intervino personalmente para elogiarlo:
Parece que se ha invertido mucho tiempo en el SLAM. Enhorabuena por los resultados.
Davison casi nunca comenta públicamente proyectos de ingeniería concretos. Cuando vuelve a publicar algo activamente y utiliza la palabra “impresionante”, la gente del sector le echa un vistazo más de cerca.

LingBot-Map enciende el mundo del SLAM: los líderes del sector dicen “por fin”
LingBot-Map hace que los robots “entiendan” de verdad el mundo entero. Su lanzamiento en código abierto atrajo a 1,2 millones de espectadores.
Muchos de los principales líderes de opinión lo reenviaron y les gustó, con lo que obtuvo un gran reconocimiento en todo el sector.
¿Qué aspecto tiene en la práctica LingBot-Map, elogiado por un pionero del SLAM y largamente esperado por los investigadores?
Las pruebas reales publicadas por el equipo dan la respuesta.
En una escena aérea, la cámara escanea toda una manzana desde arriba. LingBot-Map reconstruye las fachadas de los edificios, las estructuras de los tejados, las calles y los árboles de los bordes de las carreteras en una nube de puntos 3D completa en tiempo real.
En un escenario de navegación en interiores, la cámara se desplaza de la cocina al salón y a través de un pasillo. La iluminación y la estructura cambian constantemente, pero el mapa 3D reconstruido de varias habitaciones se alinea estrictamente en el espacio, sin desalineaciones ni imágenes fantasma entre las habitaciones.
Un pasillo con poca luz se convierte en una prueba extrema. La cámara se desplaza por un estrecho pasillo casi a oscuras. Los métodos de visión tradicionales suelen fallar en este caso, pero LingBot-Map sigue mostrando una estructura de pasillo coherente y una trayectoria estable.
Y lo que es aún más interesante, el equipo introdujo vídeos de dibujos animados generados por LingBot-World en LingBot-Map, y éste completó una reconstrucción 3D estable.
La entrada es una calle japonesa virtual generada por IA. El resultado es una nube de puntos 3D con coordenadas espaciales precisas. La compatibilidad entre ambos modelos conecta directamente la tubería de “mundo virtual → comprensión espacial 3D”.”
La comparación de trayectorias lo hace aún más claro.
En los conjuntos de datos Oxford Spires y Tanks & Temples, la trayectoria prevista por LingBot-Map (naranja) coincide casi por completo con la realidad sobre el terreno (azul), mientras que los métodos competidores TTT3R y WinT3R muestran una desviación importante.
Dentro de LingBot-Map - Un sistema de “memoria selectiva
La dificultad central de la reconstrucción 3D en streaming es una sola: cómo dejar que el modelo “construya viendo”, sin olvidar el pasado ni agotar la memoria.
La reconstrucción 3D tradicional es “capturar primero, procesar después”.”
La reconstrucción de secuencias requiere que el sistema localice y mapee continuamente mientras recibe nuevos fotogramas, todo ello controlando estrictamente los costes de computación y memoria.
Las soluciones anteriores se atascaban en los compromisos.
Algunos comprimían de forma demasiado agresiva y olvidaban gradualmente las observaciones anteriores. Algunos almacenaban en caché todos los fotogramas históricos, lo que hacía que la memoria creciera linealmente con la longitud de la secuencia. Otros combinaban modelos de aprendizaje profundo con backends SLAM tradicionales, con resultados decentes, pero que requerían un ajuste manual y carecían de rendimiento en tiempo real.
LingBot-Map toma prestada una idea estructural del SLAM clásico.
Para construir mapas mientras se mueven en entornos desconocidos, los robots necesitan mantener la memoria espacial en múltiples granularidades. El SLAM tradicional utiliza restricciones geométricas hechas a mano para gestionar esto, lo que limita la flexibilidad.
LingBot-Map internaliza esta estructura en el mecanismo de atención Transformer, lo que permite al modelo aprender qué recordar y qué olvidar.
Este mecanismo se denomina Atención Contextual Geométrica (ACG) y mantiene tres capas de memoria.
- Ancla: recuerda “dónde empecé”.”
Los primeros fotogramas actúan como fotogramas de anclaje, fijando el sistema de coordenadas y la línea de base de la escala, como las estaciones base GPS. Incluso en el fotograma 10.000, el modelo sigue sabiendo dónde está el fotograma 1. - Ventana pose-referencia: recuerda “lo que hay a mi alrededor”.”
Conserva las docenas de fotogramas más recientes con información visual completa, capturando densos detalles geométricos cerca de la posición actual, como la vista a través del parabrisas de un coche. - Memoria de trayectoria: recordar “dónde he estado”.”
Los fotogramas distantes no conservan todo el detalle visual. Cada fotograma se comprime en sólo 6 fichas compactas, que almacenan información geométrica clave de toda la trayectoria. Es como un espejo retrovisor: no ves todos los números de las calles, pero sabes de dónde vienes.
Tres capas de memoria suena complejo, pero en la práctica son extremadamente eficientes.
Para un vídeo de 10.000 fotogramas, la atención causal estándar almacena en caché unos 5 millones de tokens, mientras que GCA sólo utiliza unos 70.000. Cada nuevo fotograma añade unos 500 tokens en los métodos estándar, pero sólo 6 tokens en GCA. El crecimiento de la memoria se reduce en aproximadamente 80 veces.
Por eso LingBot-Map puede procesar vídeos ultralargos con memoria constante, mientras que otros se bloquean tras unos pocos miles de fotogramas.
Estrategia de formación de LingBot-Map y resultados de las pruebas comparativas
El equipo utilizó una estrategia de formación en dos fases.
En la primera fase, entrenaron un modelo base en 29 conjuntos de datos que abarcaban escenas de interior, exterior, sintéticas y del mundo real, construyendo una comprensión geométrica general.
En la segunda fase, introdujeron GCA y aumentaron gradualmente el número de vistas de 24 a 320, lo que permitió al modelo aprender primero secuencias cortas y luego trayectorias largas.
En la evaluación, el documento presenta los resultados de cinco puntos de referencia.
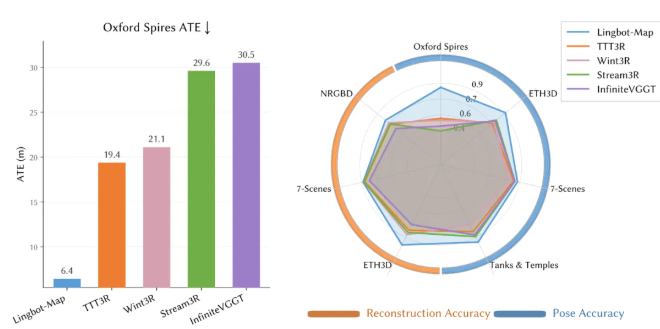
En Oxford Spires (trayectorias mixtas de interior y exterior a gran escala en la Universidad de Oxford), LingBot-Map logra un error ATE de 6,42 metros, frente a los 18,16 metros del segundo clasificado, casi 3 veces mejor.
Cabe destacar que esta precisión supera incluso a los métodos offline que procesan todos los fotogramas a la vez (12,87) y a los métodos tradicionales de optimización iterativa (10,52).
Al pasar de 320 fotogramas a 3.840 fotogramas, la ATE sólo aumenta de 6,42 a 7,11, lo que muestra una degradación casi nula con la longitud de la secuencia.
En ETH3D (con verdad sobre el terreno escaneada por láser), la reconstrucción F1 alcanza el 98,98, mejorando al segundo clasificado (77,28) en más de 21 puntos porcentuales.
En Tanques y Templos (grandes estructuras exteriores), la ATE es de 0,20 metros, frente a los 0,76 metros del segundo puesto.
En 7-Scenes (RGB-D de interior), ATE es de 0,08 metros, el mejor resultado.
Qué significa LingBot-Map para la robótica
El mundo académico se fija en ATE y F1, pero las empresas de robótica calculan una ecuación diferente.
El primero es el coste del hardware.
Un LiDAR industrial cuesta entre miles y decenas de miles de dólares. Si añadimos las IMU, las cadenas de herramientas de calibración y la adaptación del software, la percepción por sí sola puede suponer un tercio del coste total del robot.
LingBot-Map sólo necesita una cámara que cuesta unas decenas de yuanes.
Para categorías como los robots de servicio doméstico y los vehículos de reparto de baja velocidad, donde la sensibilidad al precio es extrema, eliminar el LiDAR importa mucho más que añadir otro chip.
El segundo es la navegación autónoma de larga duración.
Los robots que operan en grandes centros logísticos o entornos urbanos deben funcionar durante horas de forma continua. Los sistemas tradicionales se topan con límites de memoria en secuencias largas.
La capacidad de LingBot-Map para procesar más de 10.000 fotogramas con memoria constante hace factible la autonomía de larga duración en grandes espacios.
Otro aspecto es la manipulación con destreza.
Esto conecta con LingBot-Depth, de código abierto.
Cuando los robots intentan agarrar recipientes de cristal transparente o metal reflectante, las cámaras de profundidad tradicionales están casi “ciegas”. Estos materiales no reflejan señales fiables, lo que provoca grandes agujeros en los mapas de profundidad.
LingBot-Depth utiliza el modelado de profundidad enmascarado (MDM) para resolver este problema.
Durante el entrenamiento, se enmascaran intencionadamente partes del mapa de profundidad, obligando al modelo a inferir distancias a partir de texturas y contornos RGB.
Como resultado, alcanza un rendimiento de vanguardia en pruebas como NYUv2 y ETH3D, con una precisión de profundidad que supera incluso a la de las cámaras de profundidad industriales.
El modelo ha sido certificado por el laboratorio de visión de profundidad de Orbbec, y ambas partes han formado una alianza estratégica para desarrollar cámaras de profundidad de nueva generación. En pruebas reales, alcanzó una tasa de acierto de 50% en cajas de almacenamiento transparentes.
LingBot-Depth se encarga de “ver a qué distancia está cada píxel”, mientras que LingBot-Map se ocupa de “comprender la escena 3D completa en tiempo real”.”
Juntos, cierran el círculo de la percepción espacial para robots.
Los brazos robóticos que se enfrentan a vasos de cristal en las cocinas, tubos de ensayo en los laboratorios o contenedores metálicos reflectantes en los almacenes disponen ahora de referencias espaciales 3D fiables.
LingBot-Map completa el rompecabezas de la IA incorporada

Desde una perspectiva más amplia, la apertura de LingBot-Map no es un hecho aislado, sino un hito clave en una clara hoja de ruta de la IA incorporada.
En enero, el equipo puso a disposición pública cuatro modelos durante su “Semana de la Evolución de la Inteligencia Corporal”.”
LingBot-Depth se encarga de la percepción de la profundidad.
LingBot-VLA es un gran modelo encarnado que ha alcanzado tasas de éxito récord en el mundo real en la prueba de referencia GM-100 de la Universidad Jiao Tong de Shanghai.
LingBot-World se dirige a Google Genie 3, permitiendo la interacción en tiempo real a 16 FPS.
LingBot-VA introdujo el modelado conjunto autorregresivo del vídeo y las acciones, mejorando las tasas de éxito de las tareas en el mundo real en 20% con respecto a Pi0.5.
Pero faltaba algo.
La estimación de la profundidad proporciona “puntos” a nivel de fotograma, mientras que la cartografía 3D proporciona “superficies” continuas. La capa intermedia -comprensión espacial en tiempo real- estaba ausente.
LingBot-Map llena ese vacío con precisión.
Ahora, toda la pila de IA encarnada forma un bucle cerrado:
Ver el mundo (Profundidad) → Comprender el espacio (Mapa) → Simular la física (Mundo) → Decidir y actuar (VLA/VA)
Todos los componentes de esta cadena son de código abierto bajo licencia Apache 2.0, y el código, las ponderaciones y los informes técnicos se publican en plataformas como Hugging Face y ModelScope.
A escala mundial, este nivel de apertura es poco frecuente.
Para la industria robótica, lo que puede hacer una sola cámara acaba de ampliarse.
Referencias
- LingBot-Map. Repositorio Hugging Face (huggingface.co/robbyant/lingbot-map)
- LingBot-Map. Página de modelos de ModelScope (modelscope.cn/models/Robbyant/lingbot-map)
- Mapa LingBot. Repositorio GitHub (github.com/Robbyant/lingbot-map)
- LingBot-Map: Streaming 3D Reconstruction with Geometric Context Attention. arXiv Preprint (arxiv.org/abs/2604.14141)
- Página oficial de LingBot-Map (technology.robbyant.com/lingbot-map)

