
Short answer:
Opus 4.6 currently delivers higher reliability, lower cost, and better one-shot success rates in real-world coding workflows, while Opus 4.7 shows potential in open-ended tasks but requires more tuning, higher token budgets, and more retries to reach similar outcomes.
Opus 4.7 vs Opus 4.6: Real-World Performance vs Benchmarks
Most comparisons between Opus 4.7 and Opus 4.6 rely on controlled benchmarks. However, when evaluated inside actual development workflows over multiple days, a different picture emerges.
In a multi-day side-by-side evaluation using thousands of real coding interactions:
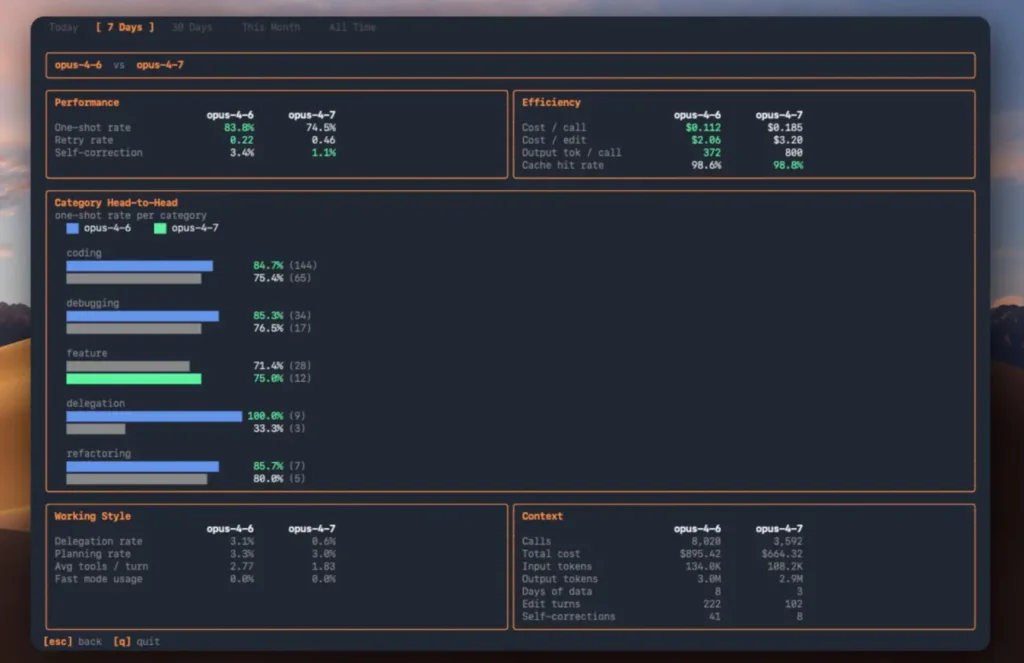
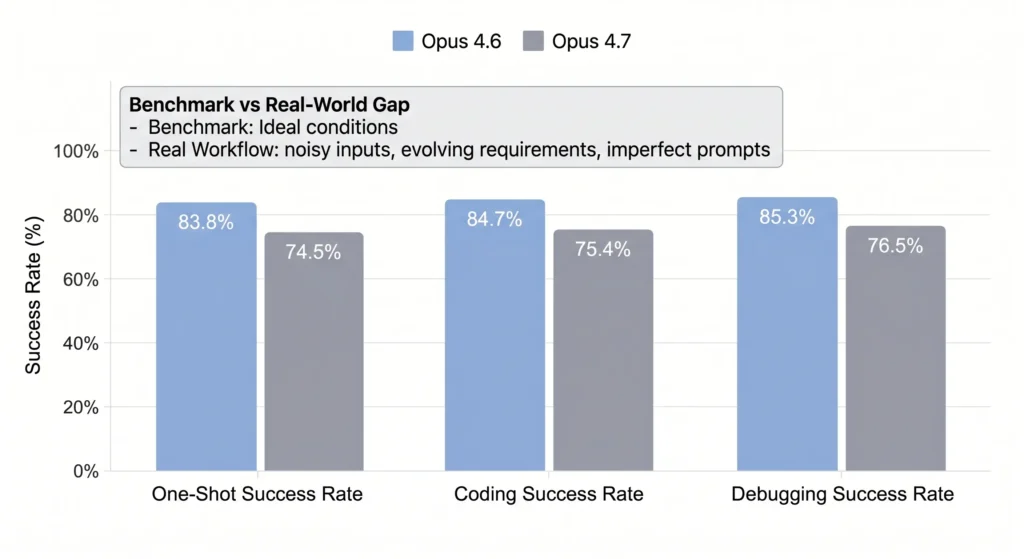
- Opus 4.6 achieved 83.8% one-shot success rate
- Opus 4.7 dropped to 74.5%
- Debugging success declined from 85.3% → 76.5%
- Coding task success fell from 84.7% → 75.4%
This gap highlights a critical distinction:
benchmark gains do not necessarily translate into production efficiency.
In practice, real workflows introduce noise—partial context, evolving requirements, and imperfect prompts. Under these conditions, Opus 4.6 proves more forgiving and reliable.
Cost and Token Efficiency: Why Opus 4.7 Is Significantly More Expensive
One of the most measurable differences between Opus 4.7 and Opus 4.6 is cost efficiency.
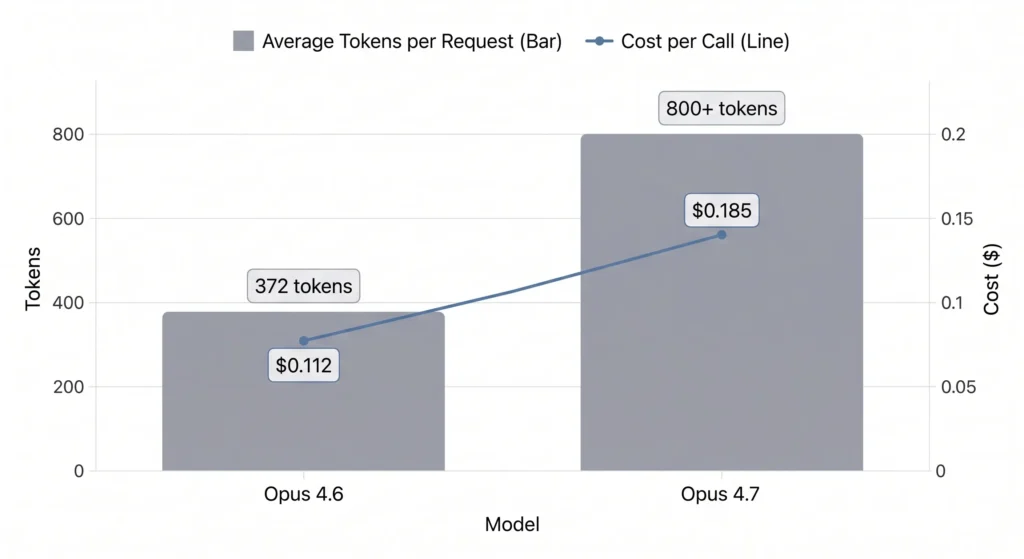
Across thousands of API calls:
- Average tokens per request:
- 4.6: 372
- 4.7: 800+
- Cost per call:
- 4.6: $0.112
- 4.7: $0.185 (+65%)
This increase is not just theoretical—it compounds quickly in real usage.
What’s Driving the Cost Increase?
- Higher verbosity
Responses are significantly longer, often including redundant reasoning. - More retries required
Failed outputs lead to additional calls, multiplying cost. - Lower signal density
More tokens do not necessarily mean better answers.
In production environments, this creates a clear tradeoff:
Opus 4.7 may be more capable in theory, but Opus 4.6 is more cost-efficient per successful outcome.
Reliability and Iteration: Why Opus 4.6 Wins in Developer Workflows
Beyond raw success rates, iteration cost is a major factor in productivity.
Measured retry rates:
- 4.6: 0.22 retries per task
- 4.7: 0.46 retries per task (≈2x higher)
This has cascading effects:
- More interruptions in workflow
- Increased cognitive load
- Context degradation over multiple turns
Real Workflow Impact
Before (Opus 4.6):
- High probability of usable output on first attempt
- Minimal correction cycles
After (Opus 4.7):
- More frequent need to refine prompts
- Higher chance of partial or incorrect outputs
- Increased back-and-forth interaction
The result is clear:
even small drops in one-shot accuracy significantly reduce overall productivity.
Case Study: 3-Day Side-by-Side Coding Evaluation
Setup
- Environment: Real-world development tasks (not synthetic benchmarks)
- Duration:
- Opus 4.7: 3,592 calls (3 days)
- Opus 4.6: 8,020 calls (8 days)
- Tools: Claude Code + codeburn analytics
Key Metrics Comparison
| Metric | Opus 4.6 | Opus 4.7 |
|---|---|---|
| One-shot success | 83.8% | 74.5% |
| Coding success | 84.7% | 75.4% |
| Debugging success | 85.3% | 76.5% |
| Retries per task | 0.22 | 0.46 |
| Tokens per call | 372 | 800+ |
| Cost per call | $0.112 | $0.185 |
Key Insight
This dataset shows that:
- Performance regression is measurable, not anecdotal
- Cost increases while success rates decline
- Iteration overhead becomes the hidden bottleneck
Case Study: Feature Development vs Debugging Performance
Interestingly, not all tasks show regression.
In feature development:
- Opus 4.6: 71.4% success
- Opus 4.7: 75% success
Although based on a smaller sample, this suggests:
- Opus 4.7 may perform better in:
- Open-ended tasks
- Exploratory coding
- Creative problem solving
But struggles with:
- Deterministic debugging
- Precision-heavy logic
- Strict correctness requirements
Interpretation
Opus 4.7 appears optimized for exploration, while Opus 4.6 remains stronger for execution.
Case Study: Tool Usage and Agent Behavior
Another unexpected finding is the decline in tool usage and delegation:
- Tools per turn:
- 4.6: 2.77
- 4.7: 1.83
- Delegation rate:
- 4.6: 3.1%
- 4.7: 0.6%
Why This Matters
Modern AI workflows rely on:
- Tool calling
- Multi-step reasoning
- Sub-agent delegation
Reduced usage suggests:
- Less decomposition of problems
- More monolithic responses
- Lower system-level efficiency
This may partially explain:
- Increased verbosity
- Lower success rates
- Higher retry counts
Prompt Sensitivity: Why Opus 4.7 Requires Re-Optimization
A consistent finding across testing is that Opus 4.7 behaves more literally.
Key Differences
Opus 4.6:
- Infers user intent
- Fills in missing details
- More forgiving with vague prompts
Opus 4.7:
- Strict instruction adherence
- Less implicit reasoning
- Requires highly structured prompts
Practical Impact
Teams migrating to 4.7 face:
- Prompt redesign costs
- System prompt rewrites
- Pipeline re-tuning
Without these adjustments, performance may appear worse than it actually is.
Creativity vs Precision: Tradeoffs Between 4.7 and 4.6
Another pattern observed across usage:
- Opus 4.6:
- More intuitive
- Better for brainstorming
- Stronger “creative feel”
- Opus 4.7:
- More rigid
- More structured
- Less stylistic variation
This leads to a clear tradeoff:
| Use Case | Better Model |
|---|---|
| Creative writing | 4.6 |
| Brainstorming | 4.6 |
| Structured pipelines | 4.7 |
| Open-ended exploration | 4.7 |
When Should You Use Opus 4.7 vs Opus 4.6?
Choose Opus 4.6 if you need:
- High one-shot accuracy
- Lower cost per task
- Reliable debugging
- Minimal prompt engineering
Choose Opus 4.7 if you need:
- Complex multi-step reasoning
- Open-ended generation
- Strict instruction following
- Pipeline control
FAQ: Opus 4.7 vs Opus 4.6
Is Opus 4.7 actually better than Opus 4.6?
Not consistently. It performs better in some open-ended tasks but underperforms in coding reliability and cost efficiency.
Why does Opus 4.7 use more tokens?
It produces longer, more detailed responses and often requires more retries, both of which increase total token usage.
Does Opus 4.7 hallucinate more?
In precision-sensitive tasks (like numerical reasoning), it shows more errors compared to 4.6 in real workflows.
Should I switch from Opus 4.6 to 4.7?
Only if you are willing to:
- Re-optimize prompts
- Accept higher costs
- Trade reliability for flexibility
Why does Opus 4.7 feel more “rigid”?
It follows instructions more literally and is less likely to infer missing context, making it feel less intuitive.
Is benchmark performance misleading?
Yes. Benchmark gains do not always reflect real-world productivity, especially in iterative workflows.
Why are retries higher in Opus 4.7?
Lower one-shot accuracy leads to more correction cycles, increasing retries and cost.
Is Opus 4.7 better for coding?
Not in its current state for most workflows. It performs worse in debugging and deterministic tasks.
Does Opus 4.7 require new prompts?
Yes. It often requires more structured and explicit prompts to achieve optimal results.
Is Opus 4.7 still improving?
Based on observed behavior, it likely requires further tuning and optimization to reach its full potential.
Final Verdict
Opus 4.7 represents a shift toward more structured, instruction-following AI—but that shift comes with tradeoffs.
For most real-world workflows today:
- Opus 4.6 is more efficient, reliable, and cost-effective
- Opus 4.7 is more experimental, flexible, but less predictable
The real takeaway is not which model is “better,” but this:
The best model is the one that minimizes retries, cost, and friction in your actual workflow—not the one that scores highest on benchmarks.

